V
主页
冲破束缚! 多层感知机+注意力机制模型准确率提升至98.85%,这11种新思路学起来
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
多模态图像融合全新里程碑:性能暴涨至99.48%,效率提升4倍!11种改进思路
Transformer颠覆性发现:像素级运算无需局部性归纳偏置 全新像素版性能再升级
涨点神器:清华提出新型注意力机制,深度学习论文创新必备!
中科院一区顶刊:即插即用的多尺度全局注意力机制 【附原文+源码】
绝了!用降噪耳机原理升级注意力? 微软亚研&清华独创Transformer
GNN新思路:17种图神经网络创新方案
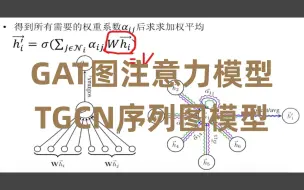
GNN+时间序列预测,新SOTA效率翻倍!迪哥精讲图注意力机制与序列图模型 轻松发文的好思路!
剑指Softmax注意力梯度下降,基于指数变换的注意力实在厉害! 深度学习这下真大升级!
(CVPR 2024)即插即用多尺度注意力机制MAB模块,即用即涨点起飞
Transformer+UNet性能显著提升!创新思路直接发了Nature!这两搭配简直就是王炸
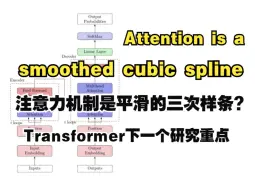
解锁Transformer的神秘面纱,探索注意力机制的数学之美!Transformer下一个研究重点
【全126集】目前B站最系统的Transformer教程!入门到进阶,全程干货讲解!拿走不谢!(神经网络/NLP/注意力机制/大模型/GPT/RNN)
重磅!Transformer再次进化! KAN加强升级!汇聚三大创新,准确率高达82%
计算机博士终于把图注意力模型(GAT)与序列图模型(TGCN)讲得如此透彻了!
直接带你把Transformer手搓一遍,这次总能学会Transformer了吧!
时序预测注意力机制模块这么好用?到2024年还能发CCF-A?即插即用、模块讲解、代码展示
奇妙的创新思路又加一个!自注意力和卷积紧密结义!3D医学图像分割混合新范式
Transformer涨点神器 引入记忆机制 高效提升SOTA指标 CV视觉任务最优#cached Transformer #backbone
Transformer+目标检测:CV领域超好出论文的方向!源码复现+模型精讲+论文解读,迪哥带你轻松搞定论文创新点!DETR/YOLO/计算机视觉
颠覆传统的图神经网络,非卷积版火爆来袭! 复杂图数据分析任务的神器
【NeurIPS2024】 贝叶斯深度学习新突破:通过超球面能量最小化,大增模型多样性!100%改进不确定性估计
【ChatGPT4.0手机版】国内无需魔法,无限次数使用教程来了!
搞深度学习牢牢抓住这五点,可以说没有找不到的论文创新点!都能让导师眼前一亮!
昆仑万维首席颜水成新作:多头注意力迎来究极形态,性能爆表!仅需50-90%注意力头
值得关注的CV方向:压缩注意力,多头双向交叉注意力新模块,适用于图像和视频等视觉模态
新神经网络模型=边界注意力!在任何分辨率下学习寻找微弱边界
【即插即用】2023 线性注意力模块
涨点必备-2024CPCA注意力机制,具备聚焦信息渠道和重要区域的能力!!
深度学习缝了别人的模块,创新点如何描述?附魔改注意力机制+多尺度特征融合模块源码
实话实说深度学习创新点小也能发论文!但是这几点你不能不知道!
神经网络全新图表示法:利用图神经网络和Transformer 特别擅长处理不同架构
小波变换+Transformer荣登Nature!预测误差降低36%!
时间序列不同注意力机制哪种更优秀?让我们一探究竟
视觉Transformer喜提金字塔结构:多阶段Token聚合,复杂度超低! CV任务变得更简单了!
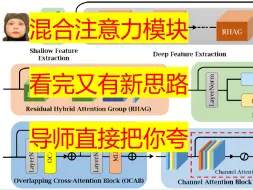
【即插即用】CVPR 2023 混合注意力模块
RNN崛起,再创Transformer!谷歌新架构两连发,同等规模强于Mamba,13种Transformer热门改进
7.控制输出平滑度的技巧:带温度的Softmax-最好的Transformer教学视频:通过图形化方式来理解Transformer架构
极长序列处理任务的神:全新联想递归记忆Transformer,5000万Token任务达79.9%准确率
【B站强推!】这可能是B站目前唯一能将【3D点云+三维重建】讲清楚的教程了,看完小白也能信手拈来,建议收藏!计算机视觉|点云
GNN新改进原地封神! 未来可能无需归一化层或自归一化,避免激活值爆炸