V
主页
绝了!用降噪耳机原理升级注意力? 微软亚研&清华独创Transformer
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
VQ(矢量量化)一下子Key:Transformer的复杂度就变成线性了?
视觉Transformer背后的关键,清华&Meta提出HorNet:用递归门控卷积进行高阶空间和相互作用(原文和代码)
【ICLR2024】 几乎零计算开销!100%改进不确定度估计 贝叶斯神经网络的神
顶会项刊=注意力机制+可变形卷积?竟然提速80%,不得不看的11种前沿创新
[速领]效果暴涨!基于Transformer的最新时序异常检测模型
少即是多!谷歌新型注意力伟大无需多言,比常规Transformer内存使用量少47倍!
超强Trick!如何设计一个比Transformer更强的CNN Backbone
即插即用-2024ICLR 自适应多尺度时序注意力机制模块!可拥有时序预测,异常检测!
没有人比苹果更懂转译!高通微软加一起都不够打的
多模态图像融合全新里程碑:性能暴涨至99.48%,效率提升4倍!11种改进思路
【物理信息神经网络】唯一一本系统讲解PINN的书籍,中英双版+源码
topos theory视角分析Transformer神经网络,注意力机制居然是关键创新? 含55种注意力机制创新
涨点神器:清华提出新型注意力机制,深度学习论文创新必备!
几乎优化任意损失函数,不使用一阶信息的新boosting算法,偏移量预言机是关键!
可解释聚类又“炸出圈”啦!把准3个切入点言路开挂,11种创新思路一学就会~
华为提出时序预测Mixers,取代Transformer,实现效果速度双提升#人工智能 #ai #论文 #时间序列#Transformer
树注意力仅需30行代码,500万长文本推理提速8倍!让GPU能省则省
Transformer提升效率的最好方法:频域核化,成本大幅降低 推理加速
softmax自注意力机制如何使Transformer模型在上下文学习任务表现出彩?
【ICLR 2024】交叉熵损失竞品出现!基于最优传输思想的损失函数
微软应用商店全新升级,带来1000+应用和游戏
英伟达发布最新魔改注意力:简单模型结构+全局信息聚合,SimplifyFormer延迟降低37%,吞吐量提高44%
CNN+LSTM+Attention,实现最高预测精度!
研究团队疯狂打脸的Nature神作:神经网络和人一样有空间意识? 首次学会在Minecraft创建地图
眼观六路 手感八方,机器手识别万物,登Science子刊封面
【NeurIPS2024】 贝叶斯深度学习新突破:通过超球面能量最小化,大增模型多样性!100%改进不确定性估计
涨点新神器-小波卷积:准确率飙升26.2%,运行时间降低60%!必看的8种结合创新思路
CNN、Transformer等之外更高效的视频理解技术来了!速度快6倍,GPU需求减少40倍
Transformer继任者:RetNet Vision版来了!超越Swim Transformer5个点
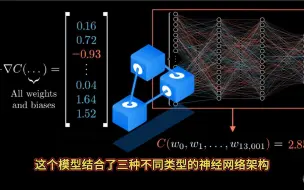
最强神经网络可视化工具:3D可视化,卷积、池化清清楚楚!一次看懂神经网络到底干了啥!
ViT性能提升必备!9个视觉Transformer最新改进方法汇总
一个不太卷的方向:时序卷积回归赛道,ICLR高分论文给你惊喜!
清华提出雪花反卷积网络,用于点云形状补全与生成,附原文和代码#人工智能 #ai #论文 #卷积神经网络 #点云
神经网络全新图表示法:利用图神经网络和Transformer 特别擅长处理不同架构
顶会=频域+注意力机制?浮点运算次数竟狂降98%,看最新12种创新思路
【速领原文和代码】谷歌新作|基于k-means的Transformer
鲁棒卡尔曼滤波2024新算法:基于广义贝叶斯推断计算高效 泛用于在线滤波各种问题
【NeurIPS2024】Transformer还有多少算法能力是我不知道的?MIT大佬力作带你一探究竟
AI顶会大热门:域自适应突破瓶颈,刷新SOTA!性能提高至92.45%
数学视角下的Transformer!MIT数学系的Philippe Rigollett主讲,UCL助理教授Haitham精讲论文,自注意力机制、深度神经网络