V
主页
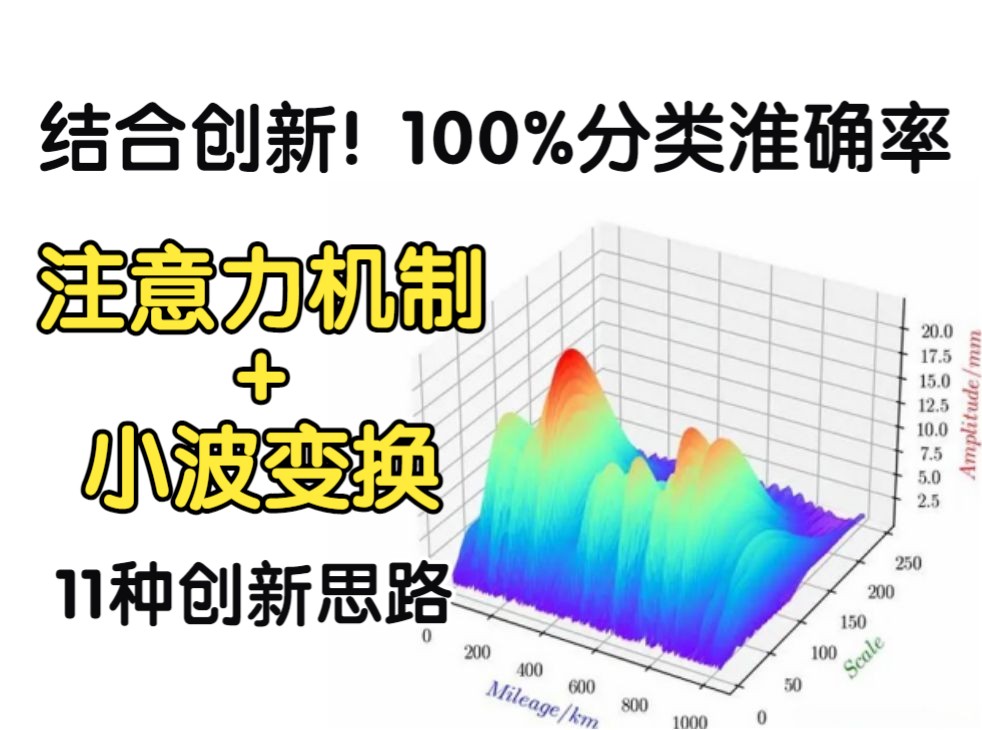
最好的结合创新:小波变换+注意力机制,实现100%分类准确率!11种创新手法
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
新改进! LSTM与注意力机制结合,性能整个拿捏住!来看9种创新思路
多尺度注意力机制突破性成果!低成本、高性能兼备的17种创新思路
时间序列异常检测新突破:登上Nature,检测准确率飙升!37种创新方法
Attention永不言败!损失函数+注意力机制再战性能巅峰,10种结合思路!
具身机器人结构化建模新热潮:掩码注意力增强Transformer,通杀MLP和基线T模型!
目前最强Backbone:北大+港大+腾讯+复旦+蚂蚊联合发布,远超ResNet
【人工智能找创新】基于注意力机制特征融合方法创新
清华提出最新移动端高效网络架构注意力机制与卷积的完美融合
太牛了!最新交叉注意力机制,内存消耗减少91%!10种魔改给你思路
都2024了,不理解自注意力可不行,趁现在从0熟悉写代码实现
Transformer+U-Net全新突破:荣登《Nature》,模型准确率暴涨至99.97%!最新14种创新手法
腾讯AI Lab开源全新注意力机制:助力视觉任务疯狂涨点!
大模型都在用的注意力加速优化Flash Attention到底稳定吗?#Wasserstein距离 #数值偏差
Transformer最新进展:性能大幅度超出一众SOTA模型!26种魔改方法
论文新思路:双通道卷积神经网络的8种创新!最新成果准确率近100%
结合创新:Patch+Transformer,计算成本狂降4倍!12种创新思路借鉴
解决数学问题的语言模型,仅20亿参数/超八位数乘法/准确率近100%!【论文原文就绪】
解锁Transformer的神秘面纱,探索注意力机制的数学之美!Transformer下一个研究重点
时序研究找不到论文/代码?一网打尽的宝藏仓库,附分类标签和一键筛选
即插即用模块,让模型say:我不确定,训练速度提升180倍!
【ICCV2023回顾】一行代码即可见效,轻量注意力再升级!
知识图谱构建与应用等12类开源工具整理 从开放知识库到知识抽取再到推理可视化
【卓卓】如何最直接、通俗地理解Transformer?
即插即用的注意力模块激活更多有用的像素
Patch才是时序预测的王道?最新工作超越Transformer取得SOTA
权重初始化新方法:大模型权重初始化小模型,训练省时又涨点!
无需看书、听课!学懂Transformer看这两篇博客就够了!
比GPT-4还强!20亿参数模型做算术题,准确率几平100%【原文和代码已下载】
长视频生成崛起!首次利用分布式并行计算,5分钟生成2300帧长视频
好中顶会:残差模块+Transformer刷爆SOTA!浮点运算次数直降62%,11种结合创新思路
小模型的组合能否实现大模型性能?这篇论文你必须估摸一下!
小样本学习登Nature:计算效率高170倍,彻底起飞!附16种前沿创新方法
多模态大模型的文字识别能力之痛,由OCR大模型来缓解!
2024年发论文方向推荐:因果推断,所有论文已汇总!
LSTM与GAN高效设计,如喝水一样产出创新点!9种主流结合思路
2080Ti跑70B大模型!上交新框架让LLM推理增速11倍,一经发布引爆业界
深度学习最好做的idea,人人都能用!有手就会的26种创新思路
对比偏好学习,不使用强化学习即可实现人工反馈学习【原文+代码】
视觉GPT利用视觉prompt分割方物
融合Transformer与CNN,实现各任务性能巅峰,17种创新参数直接减少80%