V
主页
京东 11.11 红包
【ollama】(5):在本地使用docker-compose启动ollama镜像,并下载qwen-0.5b模型,速度飞快
发布人
【ollama】(5):在本地使用docker-compose启动ollama镜像,并下载qwen-0.5b模型,速度飞快
打开封面
下载高清视频
观看高清视频
视频下载器
【ollama】(3):在linux搭建环境中,安装ollama工具,并且完成启动下载gemma:7b和qwen:1.8b运行速度飞快,支持http接口和命令行
【ollama】(6):在本地使用docker-compose启动ollama镜像,对接chatgpt-web服务,配置成功,可以进行web聊天了,配置在简介里
【ai技术】(3):树莓派4,成功安装ollama软件,内存4G,安装命令行版本,使用raspi-config配置wifi,速度9 t/s
【ollama】(7):使用Nvidia Jetson Nano设备,成功运行ollama,运行qwen:0.5b-chat,速度还可以,可以做创新项目了
【ollama】(2):在linux搭建环境,编译ollama代码,测试qwen大模型,本地运行速度飞快,本质上是对llama.cpp 项目封装
【ai技术】(4):在树莓派4上,使用ollama部署qwen0.5b大模型+chatgptweb前端界面,搭建本地大模型聊天工具,速度飞快
推荐国内使用hub.atomgit.com下载docker镜像,速度快,镜像经过安全扫描,常用的开发工具,软件都有啦!
【LocalAI】(6):在autodl上使用4090部署LocalAIGPU版本,成功运行qwen-1.5-32b大模型,占用显存18G,速度 84t/s
【ollama】(4):在autodl中安装ollama工具,配置环境变量,修改端口,使用RTX 3080 Ti显卡,测试coder代码生成大模型
【LocalAI】(4):在autodl上使用3080Ti部署LocalAIGPU版本,成功运行qwen-1.5-7b大模型,速度特别快,特别依赖cuda版本
【LocalAI】(5):在autodl上使用4090Ti部署LocalAIGPU版本,成功运行qwen-1.5-14b大模型,占用显存8G
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
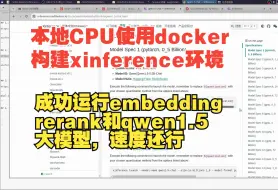
【xinference】(16):在本地CPU上,使用docker-compose运行xinference和chatgpt-web项目,运行0.5B和1.5B
【xinference】(14):在compshare上,使用nvidia-docker方式,成功启动推理框架xinference,并运行大模型,非常简单方便
【candle】(4):使用rsproxy安装rust环境,使用candle项目,成功运行Qwen1.5-0.5B-Chat模型,修改hf-hub下载地址
【compshare】(3):使用UCloud(优刻得)的compshare算力平台,新增加SD-webui和大模型镜像,可以快速启动,非常方便,部署特别简单
【LocalAI】(7):在autodl上使用4090D部署,成功部署localai-cuda-12的二进制文件,至少cuda版本是12.4才可以,运行qwen
1小时使用RAGFlow+Ollama构建本地知识库!采用OCR和深度文档理解结合的新一代RAG引擎,windows、docker
OpenHarmony 触觉智能rk3588开发板部署ollama玩转大语言模型
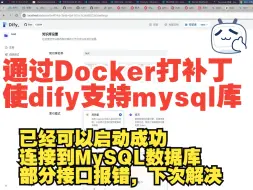
【Dify知识库】(8):使用Docker镜像打补丁方式,解决Dify升级,且需要支持MySQL数据库。可以启动成功,并读取MySQL数据库数据。
使用llama.cpp项目bin文件运行,glm4-chat-9b大模型,速度不快,建议选择量化小的Q2试试
【LocalAI】(8):使用LocalAI镜像,本地使用CPU运行stablediffusion组件,可以生成256x256的图片,生产速度较慢
【LocalAI】(9):本地使用CPU运行LocalAI,一次运行4个大模型,embedding模型,qwen-1.5-05b模型,生成图模型,语音转文字模型
【xinference】(9):本地使用docker构建环境,一次部署embedding,rerank,qwen多个大模型,成功运行,非常推荐
【LocalAI】(1):localai项目学习,通过使用docker形式,使用golang+grpc的方式实现本地大模型运行
特别推荐!在modelscope上可以使用免费的CPU和限时的GPU啦,成功安装xinference框架,并部署qwen-1.5大模型,速度7 tokens/s
【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型
【大模型知识库】(2):开源大模型+知识库方案,docker-compose部署本地知识库和大模型,毕昇+fastchat的ChatGLM3,BGE-zh模型
【LocalAI】(11):本地使用CPU运行LocalAI,一次运行5个能力,embedding模型,qwen-1.5-05b模型,生成图模型,语音转文字互转
【compshare】(1):推荐一个GPU按小时租的平台,使用实体机部署,可以方便快速的部署xinf推理框架并提供web展示,部署qwen大模型,特别方便
【OrangePi】(2):香橙派OrangePi AIpro设备,安装xinference框架,运行qwen1.5大模型
【xinference】(15):在compshare上,使用docker-compose运行xinference和chatgpt-web项目,配置成功!!!
【LocalAI】(2):LocalAI项目学习,使用hf-mirror.com镜像下载phi2大模型,通过克隆项目实现
自制Cuda大模型推理框架-讲解一个从零手写的Qwen2.5推理
【Dify知识库】(9):使用Docker镜像打补丁方式,解决Dify0.4.7版本,支持MySQL数据库。解决统计查询问题,演示Dify0.4.7版本功能
pythonstock开源股票系统(1):概要介绍/说明,使用docker-compose本地运行启动,初始化数据库,可以进行web展示
【xinference】(11):在compshare上使用4090D运行xinf和chatgpt-web,部署GLM-4-9B-Chat大模型,占用显存18G
喜大普奔 使用ollama本地部署最大模型社区海量模型,ollama安装及部署手把手教程,hugginface里有各种llm,finetune好的无审查的等
【LocalAI】(3):超级简单!在linux上使用一个二进制文件,成功运行embeddings和qwen-1.5大模型,速度特别快,有gitee配置说明
Gorse Go 推荐系统引擎,可以使用docker-compose本地运行,github有8.5k星