V
主页
京东 11.11 红包
【LocalAI】(1):localai项目学习,通过使用docker形式,使用golang+grpc的方式实现本地大模型运行
发布人
localai项目学习,通过使用docker形式,使用golang+grpc的方式实现本地大模型运行 项目地址:https://github.com/mudler/LocalAI aio 的镜像里面包括很多功能: Text to Speech (TTS) Speech to Text Function calling Large Language Models (LLM) for text generation Image generation Embedding server
打开封面
下载高清视频
观看高清视频
视频下载器
Docker动手入门 | 大模型工程师必备技能 (🎉已完结)
pythonstock开源股票系统(1):概要介绍/说明,使用docker-compose本地运行启动,初始化数据库,可以进行web展示
【LocalAI】(2):LocalAI项目学习,使用hf-mirror.com镜像下载phi2大模型,通过克隆项目实现
NAS3个有趣的项目丨这才是正确打卡方式
让飞牛NAS中的Docker使用更简单~飞牛懒人包,一键安装全部程序,重装更简单~
【xinference】(9):本地使用docker构建环境,一次部署embedding,rerank,qwen多个大模型,成功运行,非常推荐
5分钟docker动画详解
用docker搭建一个网页版的SSH/RDP/VNC连接工具!
【chatglm3】(7):大模型训练利器,使用LLaMa-Factory开源项目,对ChatGLM3进行训练,特别方便,支持多个模型,非常方方便
【LocalAI】(3):超级简单!在linux上使用一个二进制文件,成功运行embeddings和qwen-1.5大模型,速度特别快,有gitee配置说明
千万不要学node!
推荐国内使用hub.atomgit.com下载docker镜像,速度快,镜像经过安全扫描,常用的开发工具,软件都有啦!
【xinference】(14):在compshare上,使用nvidia-docker方式,成功启动推理框架xinference,并运行大模型,非常简单方便
【LocalAI】(9):本地使用CPU运行LocalAI,一次运行4个大模型,embedding模型,qwen-1.5-05b模型,生成图模型,语音转文字模型
Go语言入门到精通(golang教程)
2024最新最详细教程完整版【DevOps教程】全套入门到精通课程,Linux运维工程师必修(kubernetes(k8s)+docker)需要的来!
一个视频解决docker镜像无法拉取的问题,亲测可用的镜像加速器分享给大家
【LocalAI】(6):在autodl上使用4090部署LocalAIGPU版本,成功运行qwen-1.5-32b大模型,占用显存18G,速度 84t/s
【wails】(1):使用go做桌面应用开发,wails框架入门学习,在Linux上搭建环境,运行demo项目,并打包测试
【xinference】:目前最全大模型推理框架xinference,简单介绍项目,咱们国人开发的推理框架,目前github有3.3k星星
Docker 6分钟快速入门
【ai技术】(1):发现一个大模型可视化项目,使用nodejs编写的,llm-viz,可以本地运行展示大模型结构。
【B站最强小白运维课】2024年【k8s企业级DevOps实战】与源码解析最新版,入门级到精通全套完整课程,Linux运维,面向实战学习才是对!
【Dify知识库】(1):本地环境运行dity+fastchat的ChatGLM3模型,可以使用chat/completions接口调用chatglm3模型
紧急通知… docker镜像站被封后续,docker pull从dockerhub上拉镜像,又没法拉取了,上次整理的镜像加速器地址又又不能用了,重新整理一些可以
深度学习模型的轻量化部署:从高效剪枝到性能优化全解析-PyTorch、YOLO、TensorFlow模型部署,Mobilenet、docker
【xinference】(15):在compshare上,使用docker-compose运行xinference和chatgpt-web项目,配置成功!!!
【LocalAI】(12):本地使用CPU运行LocalAI,piper语音模型已经切换到了hugging faces上了,测试中文语音包成功!
使用docker本地运行chatglm3,原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务
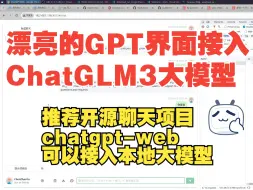
【chatglm3】(10):使用fastchat本地部署chatlgm3-6b模型,并配合chatgpt-web的漂亮界面做展示,调用成功,vue的开源项目
【大模型知识库】(3):本地环境运行flowise+fastchat的ChatGLM3模型,通过拖拽/配置方式实现大模型编程,可以使用completions接口
【LocalAI】(5):在autodl上使用4090Ti部署LocalAIGPU版本,成功运行qwen-1.5-14b大模型,占用显存8G
2小时搞定K8s企业级DevOps实践,最新云计算运维教程,手把手教
【LocalAI】(4):在autodl上使用3080Ti部署LocalAIGPU版本,成功运行qwen-1.5-7b大模型,速度特别快,特别依赖cuda版本
【wails】(7):运行llama.go项目,使用纯golang写的代码,下载了模型文件,然后可以本地执行了,可以执行,就是模型文件26G,运行速度慢
使用llama.cpp项目bin文件运行,glm4-chat-9b大模型,速度不快,建议选择量化小的Q2试试
代码+编译环境一并保存Git仓库,Jenkins使用docker编译
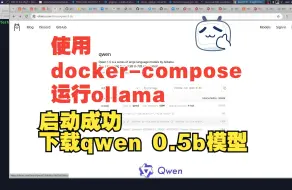
【ollama】(5):在本地使用docker-compose启动ollama镜像,并下载qwen-0.5b模型,速度飞快
2024最新最详细教程完整版【三天光速学会Docker容器技术】全套入门运维工程师必修, 需要的来!
1小时使用RAGFlow+Ollama构建本地知识库!采用OCR和深度文档理解结合的新一代RAG引擎,windows、docker