V
主页
更精准的硬币识别:硬币多模态模型 Coin-CLIP
发布人
Coin-CLIP:更精准的硬币识别多模态模型,针对硬币图片具有更强的特征提取能力,可以实现更精准的以图搜图硬币识别功能。 文字版:https://zhuanlan.zhihu.com/p/671174385 在线 Demo(美国硬币检索):https://huggingface.co/spaces/breezedeus/USA-Coin-Retrieval Coin-CLIP 开源模型:https://huggingface.co/breezedeus/coin-clip-vit-base-patch32 Coin-CLIP 开源Python工具:https://github.com/breezedeus/Coin-CLIP
打开封面
下载高清视频
观看高清视频
视频下载器
【LLM前沿】6小时精讲四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!绝对的通俗易懂的大模型应用教程!
Qwen2.5-Coder:32B开源模型私有化部署必看教程!独家讲解Qwen模型零门槛本地部署&ollama部署流程丨手把手教你玩转开源代码模型!!
【全网最新】Ollama正式支持Llama 3.2 Vision ,轻松实现本地运行多模态模型图像识别,大模型|大模型微调|大模型部署|LLM
多模态模型CLIP深度讲解
【共享LLM前沿】通俗易懂搞懂四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!大模型预训练微调
CVPR'24 | 视觉基础模型大一统?融合CLIP、DINOv2、SAM等,实现分类分割等任务上的SOTA性能
X-Portrait 2 重磅更新
【多模态+知识图谱】博士轻松带你从零构建知识图谱!基于知识图谱的六大项目实战—医药问答系统、知识抽取、推荐系统、Neo4j数据库、大模型
太超前了!谁懂智谱新开源模型“新清影”的含金量
一种交互式帧插值方法:Framer,项目即将开源
Pix2Text V1.0 新版发布,带来了最好的开源数学公式识别模型
【共享LLM前沿】假如我从11月1号开始学大模型!9小时学会搭建对话机器人办公助手、大模型预训练微调、四大多模态大模型!
视觉-语言预训练(VLP)技术介绍
绝对通俗易懂!6个小时带你啃透四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!手把手教如何训练多模态大模型!
电脑即使断网,也能轻松运行各种开源AI
CnOCR V2.3 新版发布,模型精度更高,数量更多
8G可用,Pyramid Flow miniflux版视频模型本地安装使用介绍
比LLM更重要的多模态学习(Part2)
Qwen2.5-Coder:32B 登顶全球开源模型巅峰?零成本部署丨8小时多维度实测丨Cursor&Coder实现自动化编程工作流!
UI Agents(智能体)技术
比LLM更重要的多模态学习(Part1)
基于⼤语⾔模型的 AI Agents—Part 1
使命召唤 狂怒之歌 开源模型
详解 Llama 3.1 是怎么炼成的
最新语音识别技术简介(Introduction to ASR)
如何做调研
详解本地运行大模型的三种实用渠道:Jan、LM Studio、Ollama,Hugging Face 海量 GGUF 模型可以通过 Ollama 一键运行
Finetune之后的NLP新范式:Prompt方法综述
CnOCR 纯数字识别新模型
文本检测和识别——附CnStd与CnOcr工具介绍
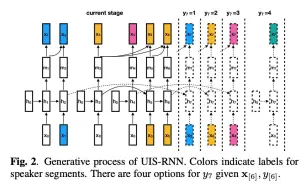
声纹分割聚类(Speaker Diarization)
RS论文阅读:你真的读懂了Youtube DNN推荐论文吗?
主动学习:如何合理使用样本先验信息
antiOCR 工具使用介绍
Talk | 西安电子科技大学曾泽群:CLIP是否有能力做零样本的图像描述生成?
超参调优框架简介
如何安装CnOCR,以及免安装直接使用CnOCR
文本摘要(Text Summarization)技术简介
基于⼤语⾔模型的 AI Agents—Part 3
NLP中的自监督学习和对比学习