V
主页
OmniBench:揭示大语言模型全方位理解能力局限性(今日Arxiv 9月24日)2024年9月24日Arxiv cs.CV发文量约182余篇,减论Agent
发布人
OmniBench:揭示大语言模型全方位理解能力局限性(今日Arxiv 9月24日)2024年9月24日Arxiv cs.CV发文量约182余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省82分钟浏览Arxiv的时间。
打开封面
下载高清视频
观看高清视频
视频下载器
2024年7月30日Arxiv cs.CV发文量约160余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省68分钟浏览Arxiv的时间
2024年7月26日Arxiv cs.CV发文量约95篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省43分钟浏览Arxiv的时间。
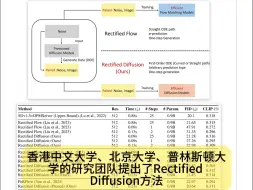
港中文提出Rectified Diffusion:更低成本,更优性能(今日Arxiv 10月11日)2024年10月11日Arxiv cs.CV发文量约147篇
高老师团队提出GeoFormer新型点云补全方法(今日Arxiv 8月14日)2024年8月14日Arxiv cs.CV发文量约85余篇
【11.1-arXiv】北大提出低秩专家混合方法提升以人为中心的图像生成能力;2024年11月1日arXiv cs.CV发文量约110余篇,减论Agent
【11.7-arXiv】北邮清华提出评估MLLM流视频理解能力基准StreamingBench!2024年11月7日arXiv cs.CV发文量约75余篇
【11.5-arXiv】浙大提出不依赖深度范围先验的多视角立体框架;2024年11月5日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐
北大提出金字塔流匹配算法用于高效视频生成(今日Arxiv 10月10日)2024年10月10日Arxiv cs.CV发文量约226余篇,减论Agent
【11.13-arXiv】西北工大提出3D聚焦多实例点云配准网络!2024年11月13日arXiv cs.CV发文量约87余篇,减论Agent通过算法为您推荐
Grounded-VideoLLM!加州大学提出视频细粒度时间定位模型(今日Arxiv 10月7日)2024年10月7日Arxiv cs.CV发文量约90余篇
英伟达重磅发布NVLM多模态大型语言模型,即将开源!(今日Arxiv 9月18日)2024年9月18日Arxiv cs.CV发文量约95余篇,减论Agent
苏黎世联邦理工学院提出文本驱动运动控制扩散模型DART(今日Arxiv 10月8日)2024年10月8日Arxiv cs.CV发文量约186余篇
复旦提出时序对比解码减少VideoLLM事件幻觉(今日Arxiv 9月26日)2024年9月26日Arxiv cs.CV发文量约120余篇,减论Agent
【11.11-arXiv】腾讯AILab提出单图生成高质量3D角色!2024年11月11日arXiv cs.CV发文量约69余篇,减论Agent通过算法为您推荐
【10.30-arXiv】华中科大提出Senna自主驾驶系统;2024年10月30日arXiv cs.CV发文量约115余篇,减论Agent通过算法为您推荐
MMFuser:南大提出多模态大语言模型视觉表征增强模块(今日Arxiv 10月16日)2024年10月16日Arxiv cs.CV发文量约126余篇
南洋理工提出Disco4D:单张图像解耦精细化服装人体(今日Arxiv 9月27日)2024年9月27日Arxiv cs.CV发文量约133余篇,减论Agent
卢老师团队提出基于SAM的显著目标检测网络(今日Arxiv 8月9日)!2024年8月9日Arxiv cs.CV发文量约68余篇。
2024年8月1日Arxiv cs.CV发文量约90余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省40分钟浏览Arxiv的时间。
MC-Bench:浙大提出多语境视觉基础任务数据集(今日Arxiv 10月17日)2024年10月17日Arxiv cs.CV发文量约96余篇,减论Agent
清华大学提出拉普拉斯混合姿态估计模型LaPose(今日Arxiv 9月25日)2024年9月25日Arxiv cs.CV发文量约128余篇,减论Agent
2024年7月29日Arxiv cs.CV发文量约60余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省26分钟浏览Arxiv的时间。
董老师团队提出底层视觉通用模型GenLV(今日Arxiv 8月19日)2024年8月19日Arxiv cs.CV发文量约75余篇
卫星图像到街景合成!上海AILab提出CrossViewDiff(今日Arxiv 8月28日)2024年8月28日Arxiv cs.CV发文量约92余篇
VLM-Grounder:港中文提出基于2D图像的零样本3D定位(今日Arxiv 10月18日)2024年10月18日Arxiv cs.CV发文量约130余篇
MedTrinity-25M:超大规模的多模态医学数据集今日Arxiv发布!包含超过2500万个图像-ROI-描述三元组!2024年8月7日
西安交大提出无需训练的开放词汇遥感语义分割方法(今日Arxiv 10月3日)2024年10月3日Arxiv cs.CV发文量约105余篇,减论Agent
【10月29日Arxiv】浙大提出OmniSep全模态声音分离框架;2024年10月29日arXiv cs.CV发文量约191余篇,减论Agent
清华鲁老师团队提出实时分割一切3D(今日Arxiv 8月22日)2024年8月22日Arxiv cs.CV发文量约110余篇,减论Agent通过算法为您推荐
【11.8-arXiv】浙大提出大规模图像到视频生成数据集TIP-I2V!2024年11月8日arXiv cs.CV发文量约100余篇,减论Agent为您推荐
中山大学提出ParGo:弥合视觉Encoder和LLM的表征GAP(今日Arxiv 8月26日)2024年8月26日Arxiv cs.CV发文量约84余篇
南开大学采用掩码建模策略提出一体化盲图像复原方法(今日Arxiv 10月2日)2024年10月2日Arxiv cs.CV发文量约95余篇,减论Agent
2024年8月6日Arxiv cs.CV今日亮点:白老师团队发力2Billion大模型,Mini-Monkey与InternVL2掰手腕!
丝滑转场!川大提出无需训练的视频过渡生成方法TVG(今日Arxiv 8月27日)2024年8月27日Arxiv cs.CV发文量约182余篇,减论Agent
前方高能,这27个变态AI,一定要偷偷用起来!
Framer:浙大提出交互式点轨迹帧插值算法(今日Arxiv 10月25日)2024年10月25日Arxiv cs.CV发文量约92余篇,减论Agent
中科大提出肖像视频编辑神器PortraitGen(今日Arxiv 9月23日)2024年9月23日Arxiv cs.CV发文量约102余篇,减论Agent
【11.15-arXiv】FAIR团队提出纯注意力迁移蒸馏方法!2024年11月15日arXiv cs.CV发文量约85余篇,减论Agent通过算法为您推荐
每日英语听读,坚持阅读100天 | 时间
清华大学提出大模型Agent开放平台LEGENT(今日Arxiv 8月20日)2024年8月20日Arxiv cs.CV发文量约242余篇