V
主页
2024年8月1日Arxiv cs.CV发文量约90余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省40分钟浏览Arxiv的时间。
发布人
2024年8月1日Arxiv cs.CV发文量约90余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省40分钟浏览Arxiv的时间。
打开封面
下载高清视频
观看高清视频
视频下载器
节省37分钟!2024年7月25日Arxiv cs.CV发文量约80余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考。
2024年7月26日Arxiv cs.CV发文量约95篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省43分钟浏览Arxiv的时间。
【11.5-arXiv】浙大提出不依赖深度范围先验的多视角立体框架;2024年11月5日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐
SENet一作率队提出袋鼠多模态大模型,支持长视频输入(今日Arxiv 8月29日)2024年8月29日Arxiv cs.CV发文量约103余篇,减论Agent
HiPrompt:使用分层提示和噪声分解生成高分辨率图像,无需微调!(今日Arxiv 9月5日)2024年9月5日Arxiv cs.CV发文量约95余篇
【11.8-arXiv】浙大提出大规模图像到视频生成数据集TIP-I2V!2024年11月8日arXiv cs.CV发文量约100余篇,减论Agent为您推荐
VLM-Grounder:港中文提出基于2D图像的零样本3D定位(今日Arxiv 10月18日)2024年10月18日Arxiv cs.CV发文量约130余篇
【11.11-arXiv】腾讯AILab提出单图生成高质量3D角色!2024年11月11日arXiv cs.CV发文量约69余篇,减论Agent通过算法为您推荐
清华大学提出拉普拉斯混合姿态估计模型LaPose(今日Arxiv 9月25日)2024年9月25日Arxiv cs.CV发文量约128余篇,减论Agent
【11.1-arXiv】北大提出低秩专家混合方法提升以人为中心的图像生成能力;2024年11月1日arXiv cs.CV发文量约110余篇,减论Agent
【10月29日Arxiv】浙大提出OmniSep全模态声音分离框架;2024年10月29日arXiv cs.CV发文量约191余篇,减论Agent
腾讯提出精准实例定位与细节生成方法IFAdapter(今日Arxiv 9月13日)2024年9月13日Arxiv cs.CV发文量约107余篇,减论Agent
复旦提出时序对比解码减少VideoLLM事件幻觉(今日Arxiv 9月26日)2024年9月26日Arxiv cs.CV发文量约120余篇,减论Agent
SRFormerV2!侯老师团队提出置换注意力解锁高性能超分辨能力(今日Arxiv 8月15日)2024年8月15日Arxiv cs.CV发文量约75余篇
清华大学提出VERIFIED自动视频文本标注流(今日Arxiv 10月14日)2024年10月14日Arxiv cs.CV发文量约93余篇,减论Agent
北理北航提出SPG解决点云语义分割类别不平衡问题(今日Arxiv 8月21日)2024年8月21日Arxiv cs.CV发文量约113余篇,减论Agent推荐
清华大学提出大模型Agent开放平台LEGENT(今日Arxiv 8月20日)2024年8月20日Arxiv cs.CV发文量约242余篇
OmniBench:揭示大语言模型全方位理解能力局限性(今日Arxiv 9月24日)2024年9月24日Arxiv cs.CV发文量约182余篇,减论Agent
Framer:浙大提出交互式点轨迹帧插值算法(今日Arxiv 10月25日)2024年10月25日Arxiv cs.CV发文量约92余篇,减论Agent
西安交大提出无需训练的开放词汇遥感语义分割方法(今日Arxiv 10月3日)2024年10月3日Arxiv cs.CV发文量约105余篇,减论Agent
【11.14-arXiv】阿里发布EgoVid-5M,含500万高质量第一人称视频!2024年11月14日arXiv cs.CV发文量约68余篇,减论Agent
清华提出条件对比对齐爆炸提升自回归视觉生成模型性能(今日Arxiv 10月15日)2024年10月15日Arxiv cs.CV发文量约242余篇,减论Agent
北京智源重磅发布Emu3:统一生成和感知的多模态大模型(今日Arxiv 9月30日)2024年9月30日Arxiv cs.CV发文量约105余篇,减论Agent
苏黎世联邦理工学院提出文本驱动运动控制扩散模型DART(今日Arxiv 10月8日)2024年10月8日Arxiv cs.CV发文量约186余篇
无需训练!UCL提出基于文本驱动的360度全景到全景翻译(今日Arxiv 9月16日)2024年9月16日Arxiv cs.CV发文量约74余篇,减论Agent
南开大学采用掩码建模策略提出一体化盲图像复原方法(今日Arxiv 10月2日)2024年10月2日Arxiv cs.CV发文量约95余篇,减论Agent
澳大利亚国立、南开团队推动结肠镜检查多模态研究(今日Arxiv 10月23日)2024年10月23日Arxiv cs.CV发文量约86余篇,减论Agent
董老师团队提出底层视觉通用模型GenLV(今日Arxiv 8月19日)2024年8月19日Arxiv cs.CV发文量约75余篇
【11.13-arXiv】西北工大提出3D聚焦多实例点云配准网络!2024年11月13日arXiv cs.CV发文量约87余篇,减论Agent通过算法为您推荐
昆士兰大学提出用于植物病害分割的大规模数据集(今日Arxiv 9月9日)2024年9月9日Arxiv cs.CV发文量约81余篇,减论Agent
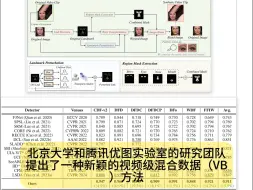
厦大提出基于物理定律驱动的单图像生成4D内容方法(今日Arxiv 9月12日)2024年9月12日Arxiv cs.CV发文量约100余篇,减论Agent推荐
2024年7月31日Arxiv cs.CV发文量约70余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省30分钟浏览Arxiv的时间
北大提出深度伪造视频检测新方法:视频混合增广+时空适配器微调(今日Arxiv 9月2日)2024年9月2日Arxiv cs.CV发文量约71余篇,减论Agent
【10.31-arXiv】中科院自动化所发布大规模车道级卫星数据集OpenSatMap;2024年10月31日arXiv cs.CV发文量约112余篇
Grounded-VideoLLM!加州大学提出视频细粒度时间定位模型(今日Arxiv 10月7日)2024年10月7日Arxiv cs.CV发文量约90余篇
丝滑转场!川大提出无需训练的视频过渡生成方法TVG(今日Arxiv 8月27日)2024年8月27日Arxiv cs.CV发文量约182余篇,减论Agent
浙大提出单目视频恢复三维人体运动新方法(今日Arxiv 9月11日)2024年9月11日Arxiv cs.CV发文量约100余篇,减论Agent通过算法为您推荐
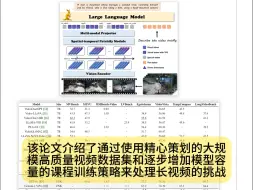
属于科研人们的暑假来了~今日Arxiv发文量显著下降;腾讯优图推出开源多多模态大语言模型VITA!视频、图像、文本、音频通通拿下(今日Arxiv 240812)
【11.18-arXiv】东南大学提出NumPro改进视频时段内容理解!2024年11月18日arXiv cs.CV发文量约99余篇,减论Agent为您推荐
Mini-InternVL:上海AI Lab提出轻量级多模态大语言模型(今日Arxiv 10月22日)2024年10月22日Arxiv cs.CV发文量约200