V
主页
1.1章-背景介绍(闲侃较多)
发布人
# 多伦多大学 07' 计算机系 # Ilya、Karpathy校友 # 自身实践AI零基础到专家的学习过程 # 降低AI门槛、复杂问题简单化讲解
打开封面
下载高清视频
观看高清视频
视频下载器
我的教授获了2024诺奖、解析他的获奖工作
DDPM的从零实现与原理讲解
如何训练自己的中文大模型分词器tokenizer?
通过看DeepSeek-v2思考目前大模型学习路径
如何训练一个写小说的大模型?
【墙裂推荐】25分钟搞定qwen大模型本地部署+微调法律大模型(只需5G内存)
清晰说明——什么是大语言模型(LLM:从零到一)【1】
Sora、Stable Diffusion、可灵文生图视频大模型原理讲解
【Llama3微调全攻略】B站最全教程!手把手教你微调-量化-部署-应用一条龙!
《Attention Is All You Need》论文解读
五分钟秒懂transformer中的神经网络
手写大模型代码(上)( LLM:从零到一)【6】
大语言模型的训练原理(LLM:从零到一)【2】
【18】大模型推理vs.训练的相同与不同
【7】手写大模型代码(中)( LLM:从零到一)
如何理解学习率
如何配置deepspeed多卡训练大模型
(超爽中英!) 2024最好的【吴恩达RAG】教程!更适合程序员,全程干货无废话,学完成为AGI大佬!(附课件+代码)
GPT大语言模型微调原理
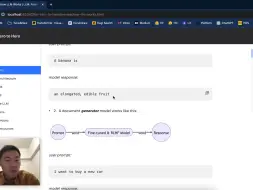
大模型实际上就是两个文件【4】
QKV里的Q啥被叫做Query? #大模型 #transformer
KAN vs. MLP架构的简单解读
Transformer里词嵌入+位置信息的深层逻辑
100万Token窗口长度的大模型背后实现技术原理
浅谈模型超参数的设计原理
Multi-Head Attention的QKV是什么【12】
LayerNorm层归一化到底做什么的?
谁都能听懂的Transformer【5】
Attention的几何逻辑(中)【9】
LayerNorm及Softmax概念(概念终)【11】
Tokenization文字转数字【6】
换一个角度理解Transformer中的QKV
训练GPT大模型需要花多少钱?【2】
彻底理解Transformer概念(LLM:从零到一)【3】
五分钟秒懂层归一化
GPT发展简史【1】
Nemotron技术拆解
先跟我一起过概念(上)【8】
闲聊:我如何从零基础实现一个月内掌握大模型!跟着我学,你也可以轻松弯道超车~
【13】Attention的QKV输出的到底是什么?