V
主页
介绍GPU最新内核优化GEMM原理 #小工蚁
发布人
介绍GPU最新内核优化GEMM原理 #小工蚁
打开封面
下载高清视频
观看高清视频
视频下载器
Qwen2-Audio语音多模态大模型使用实践 #小工蚁
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
书生200亿开源大模型开箱测试 如何在2块GPU上运行? #小工蚁 #开源大模型
LangGraph Autogen CrewAI 哪个Agent框架更好?#小工蚁
RAGChecker开源RAG诊断框架
算子优化MoE模型推理加速4倍
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
TableBench全面基于表格问答复杂任务评测框架 #小工蚁
LLaMA-Omni开源语言对话大模型,超低延时 #小工蚁
大模型推理性能优化策略 #小工蚁
人类反馈强化学习最新替代方法SimPO #小工蚁
阿里发布Text2SQL最新实践开源模型准确度超GPT4
MEMORAG受记忆启发知识发现的下一代RAG #小工蚁 #rag
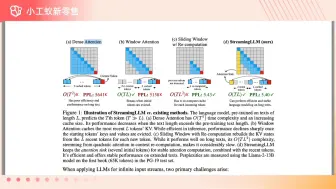
无限上下文大模型推理加速StreamingLLM #小工蚁
多模态Embedding开源模型 Visualized BGE #小工蚁
通义千问2投机解码实践演示 #小工蚁
公开课 | 智算集群技术概览——腾讯专有云首席架构师方天戟
LightLLM轻量级高性能推理框架 和vLLM哪个更强?
StreamingLLM算法让推理速度 提升22倍,支持400万Token输出
使用Triton内核加速Llama3-70B FP8推理 #小工蚁
解决内容冲突RAG算法 FILCO #小工蚁
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
使用LangChain实现Tool Calling #小工蚁
抱抱脸开源小模型SmolLM和训练数据集 #小工蚁
Qwen2.5-Coder写代码大模型技术报告解读 #小工蚁
如何消除大模型幻觉? 提高准确率 LoRA+MoE
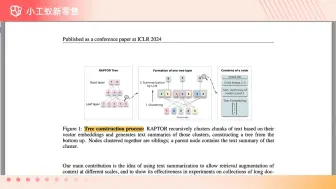
RAPTOR一种树结构检索的RAG算法 #小工蚁
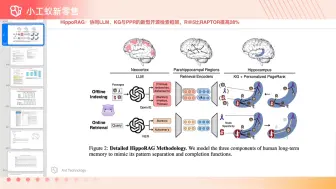
仿人脑海马体HippoRAG智能问答准确度提升 20% #小工蚁
ToolGen大模型调用工具新方法 #小工蚁
Qwen2.5-Coder阿里开源代码生成大模型 #小工蚁
OCR-2.0开源小模型实现OCR端到端应用 #小工蚁 #pdf转markdown
Jina-embedding-v3 Late Chunking演示,让RAG更准 #小工蚁
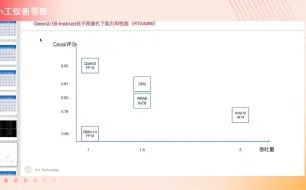
Qwen2-7B-Instruct不同量化方法准确度和性能比较
Jina Embedding v3开源多语言嵌入大模型
制造业在大模型应用如何实现降本增效 #小工蚁
HippoRAG中仿人脑海马体PPR算法实现 #小工蚁
大模型微调训练实践 准确度10%提升至90%
Jamba1.5开源大模型同等性能降低10倍KV Cache
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
多模态RAG检索增强生成2种实现方式 #小工蚁