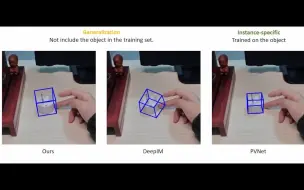
V
主页
CVPR2023|首个可用于超高质量3D数字人生成的3D扩散生成模型!支持照片或者文本描述定制
发布人
已由原作者授权以原创转载!!! https://3d-avatar-diffusion.microsoft.com/ https://arxiv.org/abs/2212.06135 AI头像制作 | 我们提出 Rodin Diffusion,这是一种用于创建高质量 3D 数字化身的 3D 扩散模型。 通过用户提供的参考图像或文本提示,Rodin Diffusion 使每个人都能轻松定制自己的头像。 我们希望这项工作能为强大的 3D 生成基础模型铺平道路。
打开封面
下载高清视频
观看高清视频
视频下载器
CVPR2024 残差去噪扩散模型(自用转载)
Meta放大招【AI重建世界】,发布首个最大的高质量3D重建数据集,实现亚毫米级的几何精度和照片级真实感
HyperHuman:基于隐式结构扩散的超逼真人像生成
CVPR2024 DCNv4:新一代高效的可变形卷积!
PODIA-3D:使用姿势保持文本到图像扩散的 3D 生成模型跨域的域自适应
【2024全宇宙最简单AI大模型项目实战-3】LangChain+RAG+LlamaIndex+Agent
Flow Matching——流匹配
CVPR2023|SINE:基于先验引导的语义驱动 NeRF 编辑
[ComfyUI]FLUX工作流深度剖析,13大模型榨干Flux模型性能,高低频采样,噪声注入。。。。
CVPR2023|HairStep:使用strand和深度图实现单视图 3D 头发建模
CVPR2023!使用文本到图像扩散模型的开放词汇全景分割
世界模拟器Movie Gen!真正超越sora!世界第一的视频模型即将开源?一致性,视频编辑,配乐音效,特效编辑,人脸识别,这才是极致!-T8 AI工具推荐
即插即用-适用所有图像任务,SPA注意力机制,秒杀Resnet!更少参数,更高指标!
「AAAI2022」图像恢复操作符 ,可用于恢复人脸修饰和高光保留曝光调整
华科提出UniAnimate:驱动单张图片跳舞,结果逼真
[李宏毅]可解释的机器学习
CVPR 2024 | 重新思考用于表面法线估计的归纳偏差
CVPR 2023 | Ref-NPR:基于参考的非真实感辐射场
ChatGPT 是如何训练的?
CVPR2023 | MetaAI最新工作ImageBind,全能AI可学习6种不同模态!
Emu3:统一理解和生成的多模态大模型
手把手教你使用服务器训练AI模型
港大&浙大提出Gen6D:从 RGB 图像估计 6 自由度物体姿势
深度学习CVPR 2023 | 图像去模糊 | 基于频域的Transformer
基于深度学习模型的解决图片过曝和曝光不足问题,数据集已开源!CVPR2021
腾讯提出精准实例定位与细节生成方法IFAdapter(今日Arxiv 9月13日)2024年9月13日Arxiv cs.CV发文量约107余篇,减论Agent
ThemeStation:输入少数示例生成主题感知的 3D 模型
ECCV 2022 | 深度图分解用于单目深度估计
兄弟们又来学跳舞了?不,学三维重建!| CVPR2021
专访27岁亿万富翁Alexandr Wang: Scale AI为AI行业提供数据标注服务,做到年化收入接近10亿
访谈《人类简史》尤瓦尔·赫拉利:阔别六年重磅力作《智人之上:AI简史》,帮你从大历史视角看待AI对我们的巨大影响
【神经网络杀疯了!】迎来人工智能新的里程碑!登上了nature神坛:被证明具有泛化能力,能像人类一样思考!
【即插即用】CVPR 2024 可形变卷积(DCNv4)
SeamlessGAN,GAN生成连贯的纹理贴图!
Vid2CAD:输入视频直接生成 CAD 模型!这个AI有点强
【比刷剧还爽!】从入门到精通CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气学完!
3D照片风格化:从单个图像学习生成风格化的新视图
智能感知、按摩、下棋、端茶倒水,新一代仿人服务机器人Walker X全球首发!
Text2Tex:基于扩散模型的文本驱动纹理合成
YOLOv11+双目立体匹配融合,进行实例分割、测距和点云重建!