V
主页
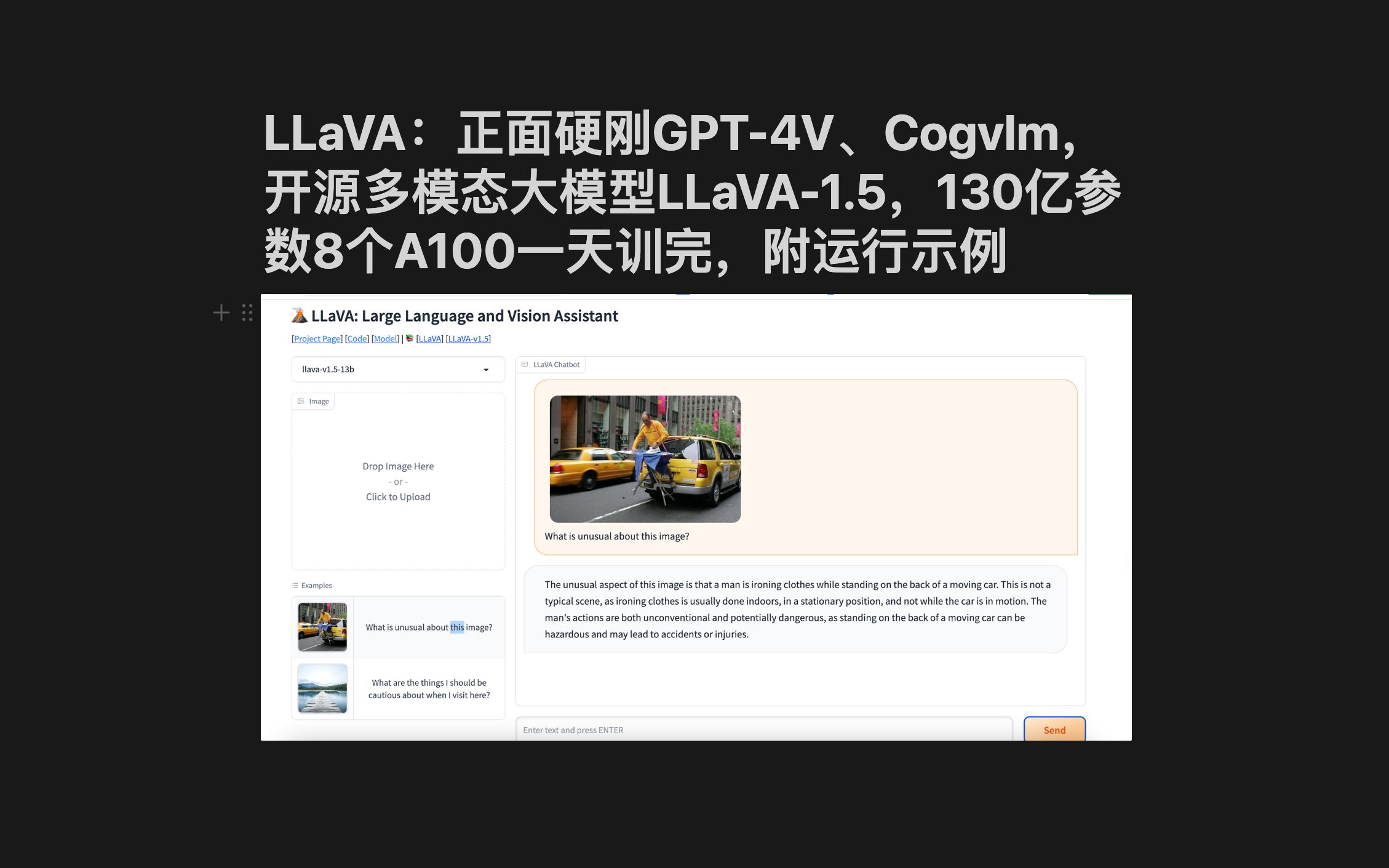
LLaVA:正面硬刚GPT-4V、Cogvlm,开源多模态大模型LLaVA-1.5,130亿参数8个A100一天训完,附运行示例
发布人
LLaVA:正面硬刚GPT-4V、Cogvlm,开源多模态大模型LLaVA-1.5,130亿参数8个A100一天训完,附运行示例
打开封面
下载高清视频
观看高清视频
视频下载器
LLaVA-1.5 正式发布!小型多模态指令数据集训练,性能媲美GPT-4V
LLaVA多模态大模型简介
体验清华多模态CogVLM的恐怖!!
多模态大模型Qwen-VL
【智谱AI开放日】CogVLM多模态技术分享
LLaVA: Visual Instruction Tuning简介
多模态论文串讲·上【论文精读·46】
Instruction Tuning (1)LLaVA 系列
Qwen-VL看图说话 2080Ti 11G显存 xinference部署多模态大模型
CogVLM:清华和智谱AI合作发布多模态模型CogVLM-17B,对标gpt-4vision,采用了类似p-tuning的方式训练visual权重
[论文速览]LLaVA: Visual Instruction Tuning[2304.08485]
智谱视觉大模型CogVLM快速上手
Video-LLaVA:宝藏AI多模态工具
LLaVA模型批量推理多张图片+细节补充
强推!科大讯飞和中科院终于把多模态大模型讲明白了,CLIP、blip、blip2三种模型原理一口气学完,看完还不会你来打我!人工智能|深度学习|多模态
多模态大模型LLaVA模型讲解——transformers源码解读
XTuner 微调 LLaVA 实践
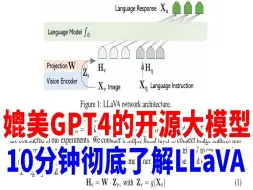
媲美GPT4的开源大模型来了!LLaVA为什么效果好?
用 ollama 跑多模态大模型 - open webui + ollama 三分钟搞定 llava 1.6
靠谱女士的组会分享[多模态大模型之clip,blip,blip–2,llava]
LLaVA媲美GPT4-V开源视觉大模型
【CogAgent】一键包 带Agent能力的视觉模型
GLM-4V:如何让大模型具备视觉理解
【初次尝试】5分钟快速了解多模态大模型LLAVA & LLAVAR
最近爆火的【多模态与大模型】到底是什么?北大博士后一小时精讲带你搞懂图像、视频、文字等信息表征是如何融入到一个大模型中的!
开源GPT4-V模型LLava, 识别图片的效果如何?
如何安装 LLaVA👀 开源免费的 “ChatGPT Vision”
清华发布VisualGLM-6B多模态模型 保姆级安装教程
详细版LLaVA模型训练—Pretrain和Finetune
Yi-VL-34B 多模态大模型 - 用两张 A40 显卡跑起来
【多模态+大模型+知识图谱】绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
我们成功了!把多模态大模型和机械臂结合到一起,效果很惊艳!
在阿里云上部署和微调VisualGLM-6B多模态大模型
本地轻松部署私有化多模态大模型,对话,图片,文档,一站式全搞定
详细版—LLaVA模型在服务器上部署和启动的过程!
清华智谱开源视觉大模型 CogVLM,可免费商用
第二代开源多模态大模型,超越GPT-4V,效果绝对让你震撼,智谱开源CogVLM2模型
最强的本地开源打标软件,支持llava-v1.6-34b,taggui
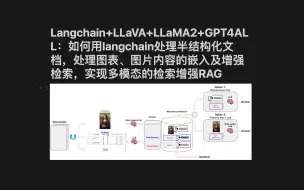
Langchain+LLaVA+LLaMA2+GPT4ALL:如何用langchain处理半结构化文档,处理图表、图片内容的嵌入及增强检索,实现多模态检索增强
安装测试MiniCPM-Llama3-V2.5多模态模型图像识别能力