V
主页
[论文速览]LLaVA: Visual Instruction Tuning[2304.08485]
发布人
论文题目:Visual Instruction Tuning / LLaVA: Large Language and Vision Asistant 论文地址:http://arxiv.org/abs/2304.08485 项目地址:https://llava-vl.github.io/ LLaVA-Med: Large Language and Vision Assistant for BioMedicine https://arxiv.org/abs/2306.00890 Flamingo: BV1pu411G7ce * 视频受up能力限制经常出现中英混杂,散装英语等现象,请见谅。如论文理解报道出了偏差,欢迎各位怒斥。 ** 新论文推荐,过往论文查找,欢迎编辑这个文档: https://docs.qq.com/sheet/DSUdOTG9xWUdydVB6 *** Slides每1-2月会上传到置顶动态地址
打开封面
下载高清视频
观看高清视频
视频下载器
多模态大模型LLaVA模型讲解——transformers源码解读
Instruction Tuning (1)LLaVA 系列
靠谱女士的组会分享[多模态大模型之clip,blip,blip–2,llava]
训练LLaVA模型(数据集构建、基于Trainer的训练框架搭建)——LLaVA系列
详细版LLaVA模型训练—Pretrain和Finetune
LLaVA多模态大模型简介
LLaVA: Visual Instruction Tuning简介
CLIP 论文逐段精读【论文精读】
硕士生去搞计算机视觉,是纯纯的脑瘫行为!
LLaVA模型批量推理多张图片+细节补充
多模态论文串讲·上【论文精读·46】
arxiv2023.10《GraphGPT: Graph Instruction Tuning for Large Language Models》
XTuner 微调 LLaVA 实践
自定义多模态大模型LLaVA——LLaVA系列
【初次尝试】5分钟快速了解多模态大模型LLAVA & LLAVAR
[论文速览]Flamingo: a Visual Language Model for Few-Shot Learning[2204.14198]
LLaVA-1.5 正式发布!小型多模态指令数据集训练,性能媲美GPT-4V
开源GPT4-V模型LLava, 识别图片的效果如何?
LLaVA:探索多模态语言模型|介绍、应用及案例【中文】
Vision Language Models MoE-LLaVA, MOBILE-AGENT, and more
LLaVA:让模型做医生,识别x片,医学映像、病例
如何安装 LLaVA👀 开源免费的 “ChatGPT Vision”
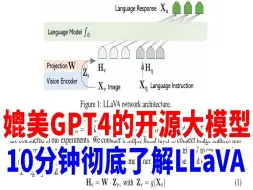
媲美GPT4的开源大模型来了!LLaVA为什么效果好?
[论文速览]LLaMA-Adapter: Efficient Fine-tuning..Zero-init Attention[2303.16199]
图解llama架构 解读源码实现
Llama 2 模型结构解析
[论文速览]OpenVLA: An Open-Source Vision-Language-Action Model[2406.09246]
【PaperReading-多模态大语言模型】多模态MoE, MoE-LLaVA
[论文速览]LoRA: Low-Rank Adaptation of Large Language Models[2106.09685]
[论文速览]Ferret-v2: An Improved...for Referring and Grounding with LLMs[2404.07973]
[论文简析]VAE: Auto-encoding Variational Bayes[1312.6114]
[论文简析]Visual Autoregressive Modeling: ...via Next-Scale Prediction[2404.02905]
[论文速览]Align before Fuse / ALBEF: ...[2107.07651]
[论文速览]LLaRA: Supercharging Robot Learning Data for VLM Policy[2406.20095]
[论文速览]Visual Prompt Tuning / VPT[2203.12119]
LLaVA:正面硬刚GPT-4V、Cogvlm,开源多模态大模型LLaVA-1.5,130亿参数8个A100一天训完,附运行示例
[论文速览]VLMs are Zero-Shot Reward Models for RL[2310.12921]
[论文简析]CLIP Dense Inference Yields Open-Vocab ... For-Free[2309.14289]
[论文简析]Regularized Vector Quantization for Tokenized Image Synthesis[2303.06424]
[论文速览]Bootstrapping Language-Image Pre-training...[2201.12086]