V
主页
【ChatLaw-Text2Vec】法律行业文本转向量模型
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
中文开源句子向量模型榜首又易主了?
自然语言处理实用教程 | 文本相似度 | 2023年版
如何对大量文本进行聚类?
如何搭建自己的文本向量数据库
为什么说14b是qwen2.5的更优解
Qwen2很好,但我选GLM4
Qwen1.5-32B 多卡推理
阿里发布中文版的 gte 文本转向量模型
使用英伟达的 tensorrt-llm 对 qwen 进行加速
4 BERT模型训练1-数据处理(构建mask 训练语料)
开源版的 GLM-4 终于来了!
链家发布中文能力更强的 whisper-large-v3
MeloTTS中英文语音合成
智源发布新版bge词嵌入模型
“扫描全能王”母公司开源的句子向量模型暂列第一
【深度干货】杨皓喆教你欧洲篮球中利用球场空间增加空切和局部配合 。
一分钟搞懂python虚拟环境
WSL安装显卡驱动和CUDA
多达8000字符的中英文句子向量模型
中文版Llama-2-13b推理
基于huggingface的中文文本分类
GNN-27.Graph U-Nets项目实战
大型纪录片《小布句子向量模型登顶》
书生·浦语或许是目前10b内最好的开源对话模型?
使用 faster-whisper 提升 OpenAI 新一代语音识别模型的推理速度
Qwen微调:单机单卡、单机多卡和多机多卡的实现
qwen大模型推理速度最快的服务搭建
SeqGPT:阿里发布适用于自然语言理解任务的大模型
更快的语音识别模型whisper-large-v3-turbo
商汤科技词嵌入模型登顶中文embedding排行榜
【AI日日新】自然语言处理实训 3.0
miniG开源大模型为何中文能力更好?
晚安!文本情感分析殿下!!
一分钟上手m3e-base微调
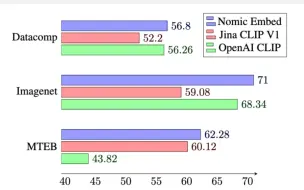
Nomic开源最新的图像转向量模型
Atom-7B:可能是目前最强的开源中文版Llama2模型
使用 qwen.cpp 项目提升 14b 模型的推理速度
医学领域的深度学习实战:Resnet+Unet+Deeplab模型及算法详解,半小时带你吃透!
ChatMusician让大模型成为音乐家
Baichuan2:新版百川模型效果更上一层楼