V
主页
Qwen微调:单机单卡、单机多卡和多机多卡的实现
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
几百次大模型LoRA和QLoRA 微调实践的经验分享
手把手教你如何使用LLaMA-Factory微调阿里千问 Qwen 大模型
Smaug开源大模型排行第一基于Qwen72B微调大模型 #小工蚁
通义千问Qwen1.5多个LoRA 同时部署和推理加速演示 #小工蚁
英伟达4090实测通义千问Qwen-72B-Chat 模型性能
【实战】通义千问1.8B大模型微调,实现天气预报功能
Windows下中文微调Llama3,单卡8G显存只需5分钟,可接入GPT4All、Ollama实现CPU推理聊天,附一键训练脚本。
ChatGLM3-6B 对比 Qwen-14B,到底谁更强?
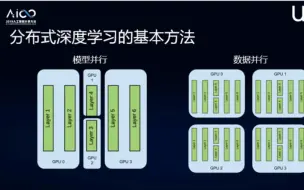
分布式多机多卡训练初体验
在服务器上部署通意千问Qwen-7B开源大模型
大模型的微调并没有那么难,小白也可以用自己的数据定制化一个属于自己的Qwen大模型,快来学习吧
最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!
【5分钟搞定】glm3微调教程没有负约!有点节目效果 ...
Qwen2很好,但我选GLM4
Qwen1.5-32B 多卡推理
CPU-双GPU联合部署Qwen1.5-72B-Chat 大模型 xinference(llama.cpp)-oneapi-fastGPT搭建本地AI助手
qwen大模型地部署和微调法律大模型(只需5G内存)
【直接可用的微调脚本】单机多卡微调ChatGLM3、Qwen,还可以接入 Tensorboard 可视化训练Loss,快来学习先人一步!
【分布式深度学习】多机多卡训练原理,开源分布式学习框架(horovod,NVIDIA Clara),配置训练流程,性能比较
llama3-06 基于llama-factory和自定义数据集进行模型微调
用 300 元的显卡推理 Qwen1.5-14B 效果展示
4060Ti16G显卡图形化微调训练通义千问Qwen模型(适合新手朋友)
双4090部署qwen72b大模型 每秒150tokens
使用 qwen.cpp 项目提升 14b 模型的推理速度
vllm-gptq 实现 Qwen 量化模型的加速推理
LlamaFactory:微调QWe (千问)模型 简单微调多数模型的便捷方法
【保姆级教程】6小时掌握开源大模型本地部署到微调,从硬件指南到ChatGLM3-6B模型部署微调实战|逐帧详解|直达技术底层
单机多卡环境下轻松部署ChatGLM3 -6B模型,合理应用与灵活管理GPU资源
一个视频让你成为AI老法师,Qwen1.5全流程最佳实践
Accelerate快速上手,多机多卡并行训练,代码实战
如何配置deepspeed多卡训练大模型
33 单机多卡并行【动手学深度学习v2】
5分钟学会微调大模型Qwen2
如何实现大模型流式回复以及 API 封装?
单卡、多卡 BERT、GPT2 训练性能【100亿模型计划】
33、完整讲解PyTorch多GPU分布式训练代码编写
4060Ti 16G显卡安装通义千问Qwen1.5-14B大模型
Qwen 量化模型应该使用 QLoRa 的方式进行微调