V
主页
京东 11.11 红包
使用ExLlamaV2消费级GPU上 运行Llama2 70B #小工蚁
发布人
使用ExLlamaV2消费级GPU上 运行Llama2 70B #小工蚁
打开封面
下载高清视频
观看高清视频
视频下载器
Qwen1.5系列6个模型如何选择? AWQ还是GPTQ?#小工蚁
Meta开源Llama2模型申请 下载和使用演示 #小工蚁 #llama2
为什么说AI芯片的最大问题不是算力,而是内存带宽? #小工蚁 #英伟达
国产首个开源MoE大模型DeepSeekMoE 16B #小工蚁
OCR-2.0开源小模型实现OCR端到端应用 #小工蚁 #pdf转markdown
ToolGen大模型调用工具新方法 #小工蚁
书生200亿开源大模型开箱测试 如何在2块GPU上运行? #小工蚁 #开源大模型
S-LORA为数千个LoRA同时提供推理,性能提升30倍 #小工蚁
近期开源VLM大模型介绍 #小工蚁
训练写万字长文大语言模型实践 #小工蚁
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
阿里开源Qwen1.5-MOE-A2.7B CEval评测 #小工蚁
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
EMU3大统一的多模态大模型 #小工蚁
LLM如何接入到个人微信? 演示群聊中AI自动回复
使用Triton内核加速Llama3-70B FP8推理 #小工蚁
多模态RAG检索增强生成2种实现方式 #小工蚁
微信小程序十亿级用户画像底层如何实现?#小工蚁 #clickhouse
Qwen2.5-Coder写代码大模型技术报告解读 #小工蚁
Reflection开源,让大模型学习“反思”
使用长上下文嵌入模型实现 延迟划块,提高RAG准确率
Qwen2-Audio语音多模态大模型使用实践 #小工蚁
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
LLM大模型应用场景2:Text2SQL #小工蚁
华为AI昇腾芯片当前重点场景是什么?#小工蚁
多模态Embedding开源模型 Visualized BGE #小工蚁
哪种模型偏好微调最优?DPO、IPO、KTO算法 #小工蚁
Unsloth微调LLM训练更快2~5倍 GPU显存省50% #小工蚁
ColossalAI助力大模型加速训练,LLaMA2训练提升195% #小工蚁 #colossalai
上下文长度达3.2万LLaMA 2 Long论文发布 #小工蚁
用GPTQ算法量化大型模型 大幅减少GPU使用并提高准确率
Llama3和Llama2模型全面对比 #小工蚁
比较3种开源大模型Roberta Llama2,Mistrial微调性能
大模型推理指令缓存功能 推理性能提升30% #小工蚁
Ollama在Mac上运行大语言模型 #小工蚁
mBART开源多语言翻译模型支持全球最常用50种语言 #小工蚁
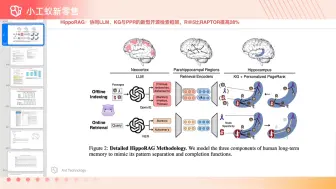
HippoRAG中仿人脑海马体PPR算法实现 #小工蚁
Ollama+Gemma2:9b本地开源大模型输出OpenAI兼容API作为本地翻译引擎工作流|Pot|OpenAI-Translator|沉浸式翻译|喂饭教程
开源AI生成声音和音乐大模型AudioLDM2 #小工蚁
探索Mistral 7B英文开源最强大模型滑动窗口注意力算法