V
主页
【腾讯文本3D生成最新工作】Dream3D
发布人
腾讯提出的文本引导的3D生成系列的最新工作。 论文地址:https://arxiv.org/abs/2212.14704 项目地址:https://bluestyle97.github.io/dream3d/
打开封面
下载高清视频
观看高清视频
视频下载器
【ICLR2023 DreamFusion】谷歌基于Diffusion Model的文本到3D内容生成工作
【北大-腾讯最新工作】T2I-Adapter 更加可控的文本生成图像
2024最好出论文的两个研究方向:Diffusion扩散模型+对比学习,源码复现+模型精讲+论文解读,迪哥带你轻松搞定论文创新点!(研一研二必看)
利用AI生成视频赚钱,一天收入500左右,全程傻瓜式操作,人人可做!
【2023 ControlNet】斯坦福最新的可控文本生成图像扩散模型
5分钟极减阅读何恺明团队最新自回归图像生成工作~从All-Token Diffusion到Per-Token Diffusion的范式转变。
【三维AIGC】扩散模型LDM辅助3D Gaussian重建三维场景
无视干扰,谷歌开源SpotlessSplats:3D场景重建中的干扰物识别与排除
浙江大学李玺教授团队、百度王井东博士合作综述:多模态可控扩散模型综述
多模态图像生成最新工作 Muse: Text-To-Image Generation via Masked Generative Transformers
【阿里最新工作】2023阿里最新可控图像合成工作Composer,生成图像的多样性优于ControlNet,T2I-Adapter
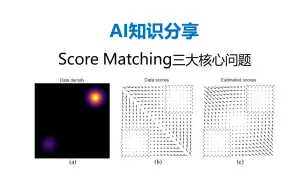
【AI知识分享】真正搞懂扩散模型Score Matching一定要理解的三大核心问题
LivePortrait 单张图片驱动虚拟人,快手联合高校开源肖像动画模型
【北大微软 可控图像生成最新工作】Unified Multi-Modal Latent Diffusion for Joint Subject and Text
提速199倍!LangSplat:清华&哈佛发布三维语义Gaussian Splatting
流模型的生成过程
【AI知识分享】结合代码深度分析ControlNet与T2IAdapter到底是如何对Stable Diffusion添加条件控制的
MOFA-Video 腾讯联合高校基于SVD多类型控制信号视频生成,开源!
强推!我居然只花了1小时就学会了【优化算法】遗传算法、蚁群算法、模拟退火算法、粒子群优化算法一次吃透!真的太简单易懂了!(人工智能、神经网络、机器学习)
一行代码,两倍去噪,三倍加速,先扩散然后去噪方法暴力涨点!必学!
【多模态学习 BLIP2的前世与今生】ALBEF, BLIP和BLIP2全系列工作串讲
【8分钟极减专栏:从分布到生成(五)】Diffusion:像优化神经网络参数一样优化出一张图像
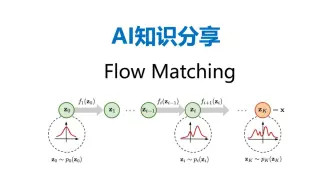
【AI知识分享】扩散模型Flow Matching基本原理深度解析
何凯明:Autoregressive Image Generation without Vector Quantizarion.
灵魂发问:知识蒸馏真的有用吗?精读AI论文
多模态图像融合全新里程碑:性能暴涨至99.48%,效率提升4倍!11种改进思路
【AI知识分享—威力加强版】理解扩散模型两大问题:为什么DDPM、DDIM中不能一步求得X0的值?为什么DDIM不能跳步过大?
利用AI生成电影解说赚钱,昨天收入600多,全程傻瓜式操作,人人可做。
OpenSora 1.2版本发布,开源!高分辨率,时长达5s。(luma、可灵、即将Gen-3,视频生成又一个热潮)
原著大佬李沐带你读《动手学深度学习》视频教程+PDF深度学习神经网络原理与代码实现 (人工智能、深度学习、机器学习算法、神经网络、图像处理、AI)
[🏆SIGGRAPH2024最佳论文提名] 3D行业的SD、ControlNet、LoRA全来了🤯
CVPR 2024 Highlight【清华、哈佛】|LangSplat:3D语言高斯溅射,告别模糊语言场,精准定义3D空间对象边界
【北大,字节】自回归图像生成模型 Visual Autoregressive Model(VAR), 通过Next-Scale预测方式实现图像生成
用扩散模型生成神经网络?NUS尤洋团队:这不是开玩笑!最新10篇扩散模型必读顶会
【大白话01】一文理清 Diffusion Model 扩散模型 | 原理图解+公式推导
3DGS官方团队新作!减少3DGS内存占用,可达29.87倍压缩,渲染速度提高1.7倍!
港中文、腾讯强推 DynamiCrafter 可控图生动画、视频新方案丨小白可玩!傻瓜教程,一键部署,轻松上手
AI新突破!分层生成3D模型,创意自由组合 csm.ai
英伟达最新!DistillNeRF:自动驾驶中从稀疏的单帧数据中完成3D场景感知
0先导片:2小时动手学习扩散模型(pytorch版)