V
主页
Vicuna+翻译,体验本地模型带来ChatGPT90%的效果
发布人
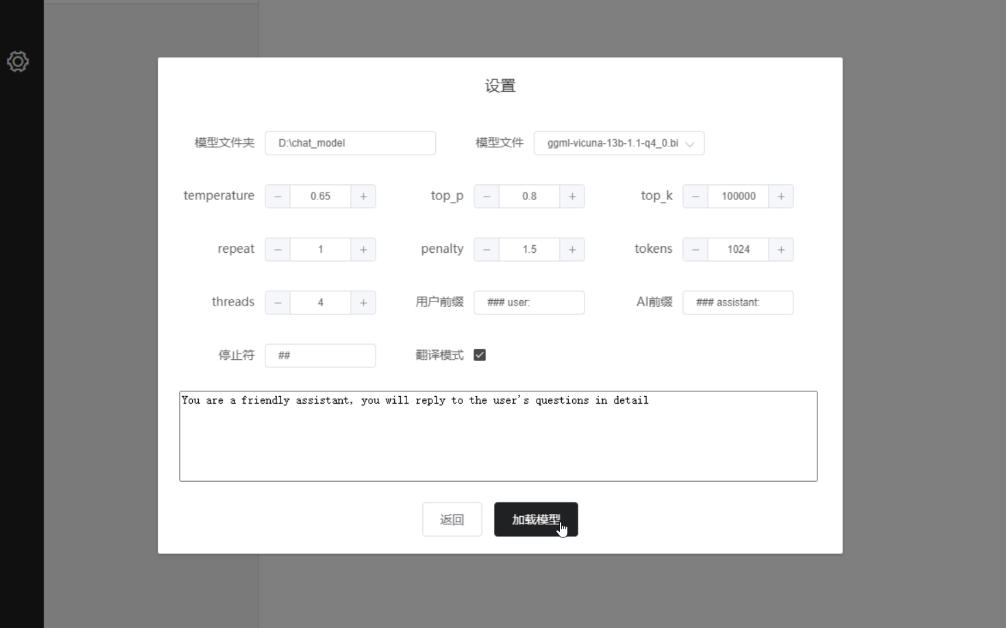
尝试使用翻译+Vicuna-13B的模型,被惊艳到了
打开封面
下载高清视频
观看高清视频
视频下载器
又一个对标ChatGPT,基于LLaMA使用ShareGPT微调的Vicuna-13B-int4测试
大模型做 OCR? Llama OCR 和 Zerox 介绍
基于llama.cpp的alpaca-7b-chinese实测
【B站最详细】使用Ollama+fastGpt搭建一个全能知识库!专属自己!支持多种文件类型,实现本地化大型模型部署,效果非凡!
【包学包会】不需要高配置!6分钟教会你使用Ollama在本机运行部署llama3.1 || 大模型本地部署、LLM、
全程干货!低成本手把手教你Fine-Tuning基于Qwen2.5-7B大模型从零微调行业大模型,过程可视化呈现
【Dify开源项目实战 】目前B站最详细的Dify快速入门教程,手把手教你基于Llama 3.1和OpenAI创建聊天机器人与知识库
30分钟教会你使用Llama Factory微调一个专属自己的中文llama3
2024吃透AI大模型(LLM+RAG系统+GPT-4o+OpenAI)通俗易懂,学完即就业!拿走不谢,学不会我退出IT圈!!!
鲨疯了!最适合新手入门的【LLM医疗大模型】教程:医疗大模型LLM应用现状及如何微调一个医疗大模型?我竟然一天就搞懂了!
在ComfyUI中使用支持IPA的Kolors节点
OpenWebUI+Ollama本地部署保姆级教程(非Docker),轻松搭建大语言模型!
用llama3美化提示词,自制节点,在comfyui中借助llama3大模型直接生成提示词
【秒懂教程】10分钟学会部署大模型GLM4,本地部署+模型微调+效果展示详细教程!草履虫都能学会~
【超低成本】Fine-Tuning基于Qwen2.5-7B大模型从零微调行业大模型,过程可视化呈现,小白也能轻松学会!
一键本地搭建大模型+知识库,1700多种开源大模型随意部罢!不挑环境、不挑配
“羊驼”开眼看世界!Llama3.2-vision视觉大测试,AI能看懂什么?
bitnet.cpp 推理,速度超越 llama.cpp,内存最高降低 16 倍 | 附 BitNet b1.58 模型安装演示
15分钟快速上手,如何为RAG选择一款合适的embedding模型?(附教程)
自制大模型在浏览器上推理:WebAssembly加速现已支持
Ollama + AnythingLLM,本地知识库+LLM 组合拳,有手就行,快速部署,大模型小白福音!
简单试跑一下SD3带T5和不带T5两个模型
【小白福音】Ollama + AnythingLLM,有手就行本地知识库部署,从安装到部署,手把手教你玩转知识库!
【Agent+RAG】10小时博士精讲AI Agent(人工智能体)系列—提示工程、文本大模型、GPT...
30分钟学会微调Qwen1.8B大模型,轻松实现天气预报功能
【自学AI Agent】绝对是我在B站见过最全的Agent智能体行业落地应用实战教程!MOE模型、LORA、RAG
从零开始,教你手搓一个精简版LLM,把参数缩减到足够单卡训练的NanoGPT,纯小白教学!
llama3提示词美化自制节点的一点小更新,演示使用glm在线推理API节点,大模型价格战后的不错的方案
【全374集】2024最新清华内部版!终于把AI大模型(LLM)讲清楚了!全程干货讲解,通俗易懂,拿走不谢!
越学越爽!25分钟学会Qwen2大模型本地部署&法律大模型微调(只需5G内存)大模型实战详细教程!草履虫都能学会~
在摩尔线程原生驱动上进行Llama.cpp的推理(没有使用vulkan)
这可能是目前市面上最全的大语言模型实用指南!!!
30分钟学会Qwen2.5-3B本地部署LightRAG,完胜GraphRAG!从模型部署到源码解读,带你全流程解析,速度快,效果好,落地部署更方便!!!
【大模型应用框架】LangChain系统教程,从零基础入门到实战!全程干货讲解,通俗易懂!(LLM/大模型/LangChain/RAG)
【2025版AI大模型教程】这可能是B站唯一能将AI大模型全讲明白的教程!存下吧,比啃书效果好太多了,7天从入门到实战,允许白嫖,拿走不谢!
【本地微调大模型】不吃配置,本地笔记本上轻松微调Llama3,Windows中文微调教程(附弱智吧训练训练集)
20分钟学会微调大模型Qwen2,本地部署+微调法律大模型,效果展示喂饭教程,草履虫都能学会!!!
Phidata:首个代理 UI - 构建具有记忆、知识、工具和推理能力的代理!(开源)
【AI大模型】使用Ollama+AnythingLLM 搭建一个本地私有化知识库!从安装到部署,手把手教你本地化RAG!
手撕代码#1|为了128K context的attention map我真的是手撕到不行