V
主页
019Spark概念04
发布人
019Spark概念04
打开封面
下载高清视频
观看高清视频
视频下载器
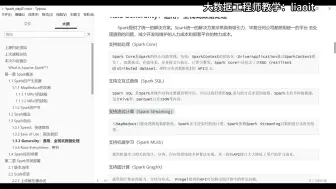
016Spark概念01
001Spark课程引言01
010Spark的产生01
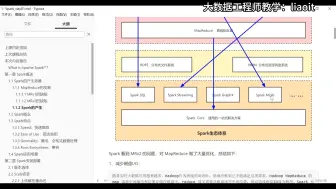
023Spark应用场景01
004MapReduce v1的缺陷01
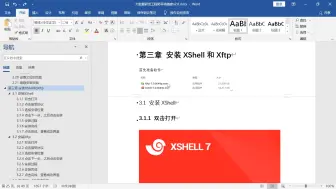
05Xshell和Xftp的安装
11Hadoop集群格式化与启动
06Xshell连接虚拟机
050Spark编写WordCount
012Spark的产生03
0088MapReduce概念8
0086MapReduce概念6
045Flink 架构设计实现和应用模块分工04
011Spark的产生02
009MapReduce v2的缺陷及解决方案
019MapReduce 框架核心流程04
006Hive 和 RDBMS 的对比01
0040HDFS优缺点
031Spark正式安装02
001Flink课程介绍01
034Flink流式计算引擎基础理论02
035Flink流式计算引擎基础理论03
0081MapReduce概念1
025Spark安装部署01官网查看
049Flink集群搭建02
024Spark应用场景02
017MapReduce 框架核心流程02
003Flink前言
0009什么是Hadoop(一)
0068HDFS心跳机制1
03VMware安装CentOS7操作系统引导过程
010MapReduce 执行引擎解析04
018MapReduce 框架核心流程03
024Spark 执行引擎解析01
0070HDFS心跳机制3+HDFS安全模式1
002Flink课程介绍02
025Spark 执行引擎解析02
022Spark特点03-Generality+04-Runs Everywhere
006MapReduce v1的缺陷03
036Flink官网解读01