V
主页
通义千问110B本地8卡魔改2080ti推理速度测试报告
发布人
模型地址:https://hf-mirror.com/Qwen/Qwen1.5-110B-Chat-GPTQ-Int4 对本地搭建有兴趣的可以参考:https://www.bilibili.com/read/readlist/rl823654 110B做的摘要:https://www.bilibili.com/read/cv34147532/ 硬件:22G魔改2080ti*8 超微4029 CPU: 6133 内存256G 推理框架:vlllm0.4 .1 可以跑满32K 上下文, 单请求:30t/s; 16请求,吞吐量:170t/s 群友交流: 4卡2080ti,可以跑9K的上下文。 4卡qwen1.5-110b 单请求20 2并发40 4并发67 8并发101
打开封面
下载高清视频
观看高清视频
视频下载器
低成本运行通义千问72B,实现高效高质翻译任务,媲美GPT4
本地运行通义千问32B!不吃配置保护隐私,可兼容AMD显卡或纯CPU
八块魔改2080ti显卡跑llama-3-70b-instruct-GPTQ
八块魔改2080ti上跑两个通义千问72B,效率翻倍,瞬时翻译,精准即达
3万字长文摘要:通义千问32B模型的长文本实力展示
8卡魔改2080ti版驱动通义千问,72Bint8展现30K上下文的强大语言处理能力
国产最强开源大模型阿里通义千问Qwen1.5-110B
通义千问千亿模型比720亿模型更省算力 #小工蚁
2080ti单卡运行Ollama:并发Llama3模型与多模型加载推理
四块魔改2080ti显卡跑llama-3-70b-instruct-awq
RTX2080ti改22g显存为何故障率这么高?(附上期视频抽奖结果)
英伟达4090实测通义千问Qwen-72B-Chat 模型性能
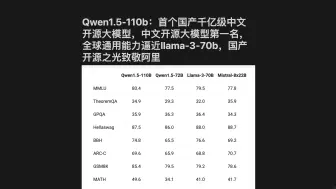
Qwen1.5-110b:首个国产千亿级中文开源大模型,中文开源大模型第一名,全球通用能力逼近llama3-70b,国产开源之光致敬阿里
Yi-34B(4):使用4个2080Ti显卡11G版本,运行Yi-34B模型,5年前老显卡是支持的,可以正常运行,速度 21 words/s
精准翻译之道:融合智能体、专业知识库与工作流的高效流程构建
"通义千问"110B大模型助力无障碍阅读英文原版书籍
4x2080ti 22G 组装低成本AI服务器跑Qwen1.5-110B-int4竟如此丝滑?
8卡魔改2080ti跑Qwen1.5 72B int4速度测试
本地革新!两块2080ti魔改显卡驱动32B通义千问,VLLM框架解锁翻译新速度
万元预算本地流畅跑Qwen1.5_72B AWQ
地表最强混合智能AI助手:llama3_70B+Yi_34B+Qwen1.5_110B
阿里巴巴开源1100亿参数Qwen1.5-110B模型#快讯
单卡魔改2080ti跑Qwen1.5 14B AWQ速度测试
AMD 7900XTX: Ollama本地运行LLama 3和Qwen大模型
通义千问千亿大模型开源性能超LLaMA-3-70B #小工蚁
CPU-双GPU联合部署Qwen1.5-72B-Chat 大模型 xinference(llama.cpp)-oneapi-fastGPT搭建本地AI助手
单卡2080Ti跑通义千问32B大模型(ollama和vllm推理框架)
高速翻译!无需等待!Sakura 1B8,Qwen 1B8以及Qwen1.5 14b 双语通用模型介绍
中文版LLAMa3 70B,性能强化,零损耗,震撼登场!
在本地环境中直接运行未经量化的全尺寸模型:Smaug-Llama-3-70B
双4090部署qwen72b大模型 每秒150tokens
八块魔改2080ti显卡满血跑Mixtral-8x22B-Instruct-v0.1-AWQ
Qwen2 72B Instruct 全量模型本地运行实测
揭晓答案:Qwen-72B和Yi-34B生产部署性能哪个更强?
最强垃圾王Tesla P40 24GB
测试Yi-1.5-34B-Chat
Windows下中文微调Llama3,单卡8G显存只需5分钟,可接入GPT4All、Ollama实现CPU推理聊天,附一键训练脚本。
省万元?!AI应用大战之22G魔改2080TI对比4090及其他显卡
八块魔改2080ti显卡跑WizardLM-2-8x22B-AWQ
TeslaP4跑LLAMa3,尝试英文翻译任务来测试中文能力