V
主页
京.东618红包,每天可领3次
Qwen1.5-110b:首个国产千亿级中文开源大模型,中文开源大模型第一名,全球通用能力逼近llama3-70b,国产开源之光致敬阿里
发布人
Qwen1.5-110b:首个国产千亿级中文开源大模型,中文开源大模型第一名,全球通用能力逼近llama-3-70b,国产开源之光致敬阿里
打开封面
下载高清视频
观看高清视频
视频下载器
中文版LLAMa3 70B,性能强化,零损耗,震撼登场!
八块魔改2080ti显卡跑llama-3-70b-instruct-GPTQ
qwen-7b 根本停不下来!
通义千问110B本地8卡魔改2080ti推理速度测试报告
小米14安装运行Qwen1.5-7B开源大语言模型(无需联网)
[测试] qwen 0.5b 1.8b 7b 14b 模型翻译文本测试 14b 效果不错 7b 可以接受
P104+P40本地部署qwen1.5 72B
精准翻译之道:融合智能体、专业知识库与工作流的高效流程构建
Tesla P40单卡部署Qwen1.5-32B
不用显卡使用70亿参数llama3及API,人人都能用都会用,免费LLM阵营王者
骁龙870处理器的老手机安装运行Qwen1.5大语言模型(可断网使用)
家庭PC本地部署LLama3 70B模型测试,对比70B和8B模型的效果,看看人工智障距离人工智能还有多远
在本地运行llama3中文版大模型AI对话,确实是太强了
将Qwen1.5大模型编译成手机可以运行的大模型
地表最强混合智能AI助手:llama3_70B+Yi_34B+Qwen1.5_110B
本地部署 Llama3 – 8B/70B 大模型!最简单的3种方法,支持CPU /GPU运行 !100% 保证成功!! | 零度解说
用 300 元的显卡推理 Qwen1.5-14B 效果展示
低成本运行通义千问72B,实现高效高质翻译任务,媲美GPT4
阿里巴巴开源1100亿参数Qwen1.5-110B模型#快讯
实测对比Kimi,通义千问,司马阅等产品文档解读能力!
4060Ti16G显卡图形化微调训练通义千问Qwen模型(适合新手朋友)
4060Ti 16G显卡安装通义千问Qwen1.5-14B大模型
实现任意大模型本地web、api部署,语音对话
ChatGLM3-6B 对比 Qwen-14B,到底谁更强?
国产最强开源大模型阿里通义千问Qwen1.5-110B
最新的Qwen1.5系列大模型已经托管在Ollama平台,这绝对是最简单高效的本地私有化部署的方法,快进来看看吧
【Qwen(1.5)入门系列指南】5小时精品大合集,快速掌握模型部署推理和应用方法,Ollama、Vllm等主流框架的集成应用逐帧详解|直达技术底层
mistral 8*22b:开源大模型第一名再次易主,但吐槽下MOE组织大模型方式是一种鸡肋的方式,相比于单一的大参数模型占用GPU一点都没省,仅仅提升了并发
通义千问Qwen1.5-32B发布,实际体验能追上ChatGPT吗?
【LocalAI】(6):在autodl上使用4090部署LocalAIGPU版本,成功运行qwen-1.5-32b大模型,占用显存18G,速度 84t/s
阿里云正式发布通义千问2.5,并开源通义千问1100亿参数模型
llama3 本地测试cpu-ollama,最强开源大模型
M3 max 48g 跑Llama3 70b 4bit
一键部署本地私人专属知识库,开源免费!可接入GPT-4、Llama 3、Gemma、Kimi等几十种大模型.。
本地微调Llama3开源大模型!用自己的知识库打造自己的专属大模型!老旧显卡也能跑得动大模型微调!
llama3使用m3max和4090的推理速度对比及企业应用
简单几步微调Llama3变身中文大模型,PDF清洗数据集并用Ollama和LM Studio加载微调好的大模型
【Qwen-VL】一键包 阿里云的大型视觉语言模型
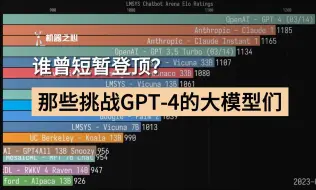
那些挑战GPT-4的大模型们,谁曾短暂登顶?
【独家】如何提升大模型数学推理能力? 微软发布可手机上部署大模型phi3-mini 3.8b,性能堪比gpt-3.5