V
主页
[NSDI2023] FLASH:一套为联邦学习设计的高性能硬件加速架构
发布人
https://www.youtube.com/watch?v=I5V3r-8sY-Y
打开封面
下载高清视频
观看高清视频
视频下载器
Mamba和S4解读:架构、并行扫描、内核融合、循环、卷积、数学
[NSDI2023] TopoOpt: 为DNN训练作业联合优化网络拓扑和并行化策略
[NSDI 2023] ModelKeeper:根据模型相似性自动化预热,进而加速DNN训练
[NSDI2023] Gemel: 边缘端基于模型合并方法的内存高效,实时视频分析
[NSDI2023] Boggart: 加速回顾型视频分析
在线ML边缘侧应用
[NSDI2023] Fluxion: 分布式系统中预测端到端延迟的模块化学习
字节万级GPU集群LLM训练
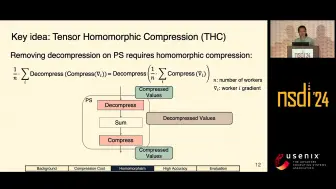
[NSDI 2024 THC:tensor同态压缩加速分布式DL训练
[HOTI2023] 高性能ML,DL,数据科学的原则和实践
Stanford EE259 惯性传感器:加速度计的工作原理与架构
[NSDI2023] 数据中心网络中可扩展长尾延迟预估
Groq张量流式处理器架构
机器人泛化学习
GPU加速
[NSDI2023] Tambur: 通过流式编码对视频会议进行高效损失修复
[NSDI2023] 使用自适应帧速率实现高质量实时通信(RTC)
[NSDI2023] SelfTune: 集群管理调优
[NSDI 2024] DISTMM: 加速多模态模型训练
[OSDI2023] Flor: 一个在异构RNICs上的开放高性能RDMA框架
[NSDI2023] CausalSim: 无偏trace-driven模拟的因果框架
[Stanford Seminar] 设计下一代自动驾驶技术栈架构
[NSDI 2024] CASSINI: ML集群中的网络感知job调度
[APNEET2023] 超大规模RDMA:经验和未来方向
基于FPGA的DL加速的高效计算内存架构
冲撞感知操控:利用有意碰撞加速任务执行
GKE上如何利用TPUs加速机器学习负载
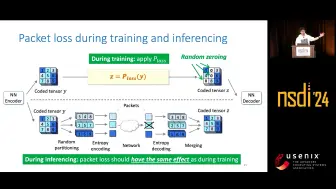
[NSDI 2024] GRACE: 通过神经编解码实现抗损的实时视频
加速数据科学:为pandas、NetworkX和Spark MLlib提供GPU加速
走向一个ML优化加速的大一统理论
针对AI工作负载优化的存储架构
GRASP on Robotics: 复杂网络的统一理论架构
Berkeley EECS研讨会讨论:Future of Robotics
CSAIL 几何深度学习:从欧几里得到药物设计
通用医学图像分割
机器人空间感知基础
[MLSys2024] AWQ:用于LLM压缩和加速的激活感知权重量化
下一代机器人感知:3D场景图,可验证算法,自监督学习
ChatGPT发布1年半后,LLMs开源生态
神经场在机器人操作中的应用