V
主页
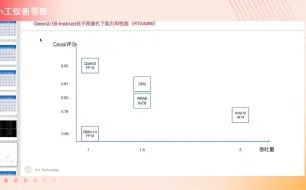
Qwen2-72B性能对比 英伟达RTX4090和L20各4卡
发布人
Qwen2-72B性能对比英伟达RTX4090和L20各4卡
打开封面
下载高清视频
观看高清视频
视频下载器
龙芯中科:9A2000显卡对标NVIDIA RTX 2080!9A3000争取跨越发展
Qwen2-7B-Instruct不同量化方法准确度和性能比较
BAdam大模型全参训练方法更省显存,速度更快,性能更优
MiniCPM3-4B开源 4B参数挑战7B性能!真的吗? #小工蚁
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
Jamba开源模型性能超越 Mixtral8*7B 采用最先进混合架构
【全网首发】最新入门级 NVIDIA RTX 专业显卡 VS 上一代,超全性能测评!
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
英伟达RTX 5090显卡参数曝光:21760 FP32+512bit 32GB GDDR7
RTX 5090不远了!RTX 4090纷纷断货:疯狂涨价近8000元!
华为盘古Pangu-Code2:如何微调出接近GPT4水平的性能?
AI服务器显卡都给我拉满!8张L20搞定350亿参数量够不够意思?
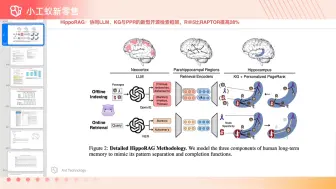
HippoRAG中仿人脑海马体PPR算法实现 #小工蚁
Yi-VL开源最强多模态大模型 #小工蚁
大模型量化技术概述
BCE Embedding开源大模型 RAG应用准确度提升关键
Qwen2-Audio语音多模态大模型使用实践 #小工蚁
AMD最强人工智能芯片发布性能超英伟达H100 #小工蚁
显卡日报9月14日|AMD显卡路线图曝光
斯坦福开源RadixAttention算法 和SGLang语言,性能再翻5倍
国产首个开源MoE大模型DeepSeekMoE 16B #小工蚁
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
混合RAG结合向量RAG和图RAG优势在哪里?
比较3种开源大模型Roberta Llama2,Mistrial微调性能
开源项目moffee 将markdown格式转为PPT #小工蚁
显卡日报9月7日|奸商全力炒作RTX4070S和4070TIS
构建多模态RAG应用实践 #小工蚁
开源最强大语言模型Mixtral 推理和训练如何使用?#小工蚁
RouteLLM大模型GPT4o调用成本下降85%,性能达到95%
显卡日报9月13日|RTX4070阉割版4K帧数损失至高10%
VLM多模态开源大模型发展迅速 下半年将成为主流
显卡日报9月20日|RTX4090/4090D停产存疑
谷歌开源gemma2大语言模型用了啥新技术?
突破极限:Yi-VL多模态模型惊艳亮相,推理加速性能压测演示 #小工蚁
微调开源模型具备Function Call讲解和演示 #小工蚁
MEMORAG受记忆启发知识发现的下一代RAG #小工蚁 #rag
SQLEval Text2SQL能力评估实践 #小工蚁
Unsloth微调LLM训练更快2~5倍 GPU显存省50% #小工蚁
大疆赋能的60000元自行车到底怎么样?Amflow PL评测
谷歌正式发布最强AI模型Gemini #小工蚁