V
主页
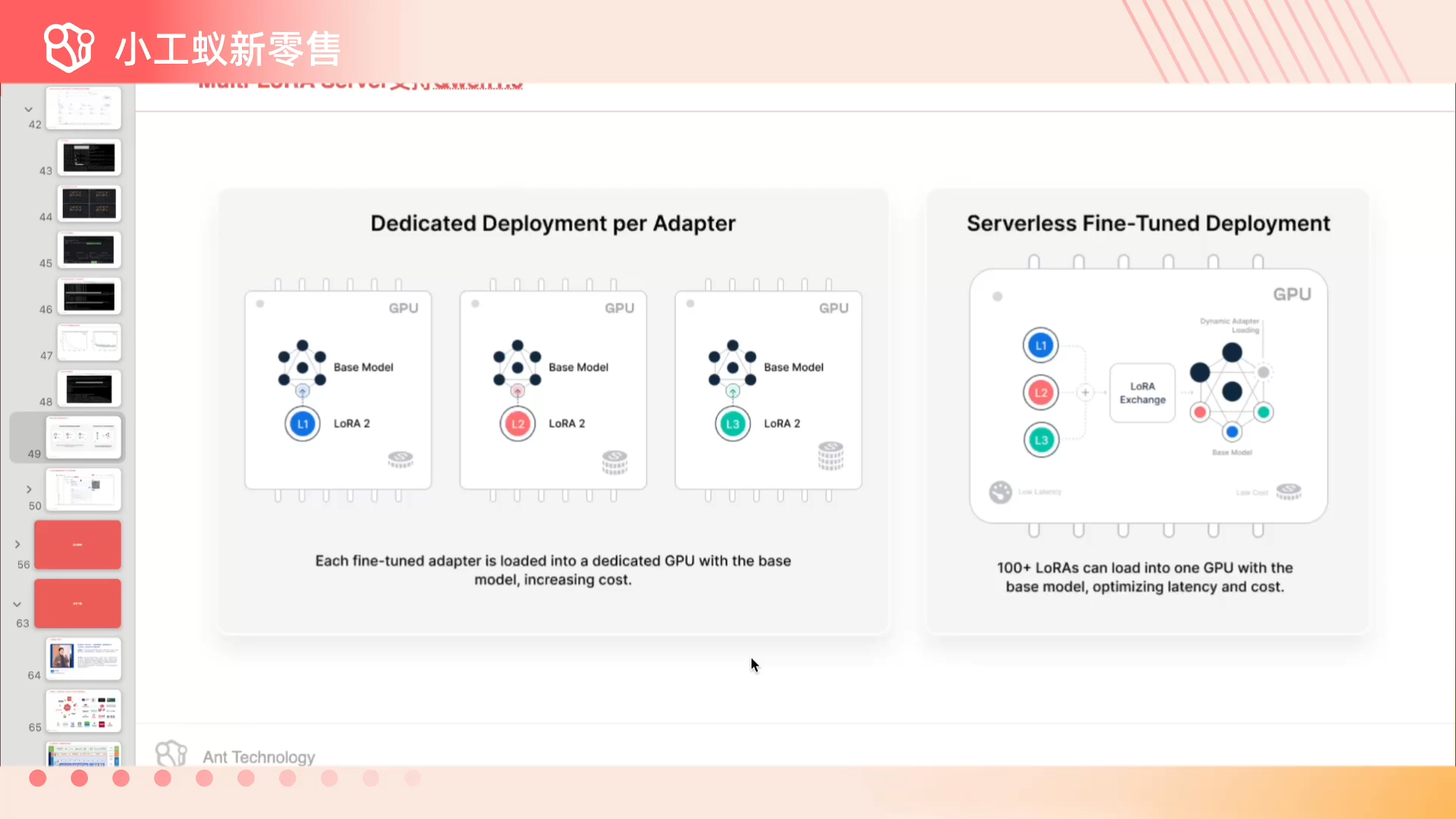
通义千问Qwen1.5多个LoRA 同时部署和推理加速演示 #小工蚁
发布人
通义千问Qwen1.5多个LoRA 同时部署和推理加速演示 #小工蚁
打开封面
下载高清视频
观看高清视频
视频下载器
Qwen1.5-72B上下文推理准确度评估演示16K时最优 #小工蚁
llama.cpp大神实现投机采样,让大模型推理性能直接翻倍 #小工蚁
几百次大模型LoRA和QLoRA 微调实践的经验分享
如何提高垂直领域RAG准确率? #小工蚁
谷歌发现RAG缩放定律 释放LLM长上下文潜力 提升RAG准确率 #小工蚁
多GPU推理加速Qwen-72B开源大模型 #小工蚁
如何测试大模型推理加速?通义千问和百川2模型测试对比 #小工蚁
如何将LLM输出文本转为结构化数据? #小工蚁 #langchain
大模型推理性能优化策略 #小工蚁
Prefix Caching原理和对大模型推理加速影响 #小工蚁
如何让大语言模型Qwen-7b使用Langchain中的工具? #小工蚁 #qwen7b
FinGPT: 轻量级适应在金融领域高效LLM解决方案 #小工蚁 #chatglm #chatgpt
通义千问2投机解码实践演示 #小工蚁
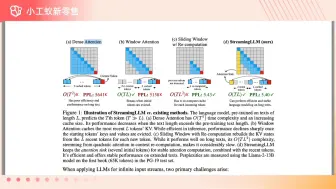
无限上下文大模型推理加速StreamingLLM #小工蚁
PyTorch原生优化Llama2推理加速,性能提升近10倍 #小工蚁
多跳智能问答EfficientRAG更胜一筹 #小工蚁
阿里发布Text2SQL最新实践开源模型准确度超GPT4
训练大语言模型LLM 如何定义自己训练数据集?#小工蚁
BurstAttention长上下文LLM推理和训练加速算法 #小工蚁
PDF文档文字、表格混排自动识别,增强RAG应用准确度 #小工蚁
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
SalesGPT开源AI销售助理演示和源代码介绍 #小工蚁 #salesgpt
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
谷歌开源时间序列大模型 直接使用不需要训练 #小工蚁
大模型推理指令缓存功能 推理性能提升30% #小工蚁
投机采样创新:多头美杜莎让推理速度提升2倍 #小工蚁
将数据源同步到向量存储,langchain解决方案 #小工蚁 #langchain
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
部署大模型在TorchServe+vLLM #小工蚁
超越文本RAG,多模态RAG实践 #小工蚁
IRCoT多次推理检索RAG算法 #小工蚁
LLM推理过程中自动缓存KV Cache功能 #小工蚁
如何评估智能问答的准确性?使用Ragas开源RAG自动评估框架 #小工蚁 #langchain #ragas
使用Triton内核加速Llama3-70B FP8推理 #小工蚁
抱抱脸开源小模型SmolLM和训练数据集 #小工蚁
打造智能客服:LLM和本地 知识库的完美协同原理
谷歌实践如何让大模型“读懂”海量表格数据?RIG&RAG #小工蚁
小工蚁开源大模型解决方案 快速部署,轻松满足定制需求
自适应RAG算法和实现
TGI让Huggingface Transformer推理速度提升10倍,本地演示 #小工蚁 #huggingface