V
主页
CVPR 2023|T2M-GPT:基于离散表达从文本生成动作
发布人
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations code: https://github.com/Mael-zys/T2M-GPT paper: https://arxiv.org/pdf/2301.06052.pdf project: https://mael-zys.github.io/T2M-GPT
打开封面
下载高清视频
观看高清视频
视频下载器
CVPR 2023|基于扩散模型的泛化音频驱动的肖像动画
CVPR 2023|SDFusion:多模态3D形状补全、重建和生成
CVPR2023|隐式扩散模型用于连续图像超分辨
CVPR 2023|布局到图像生成的可控扩散模型
CVPR 2023|A2J-Transformer:3D交互手部姿态估计
CVPR 2023|第一人称视角视频的3D手部姿势估计和动作识别
InternVL作者详解CVPR Oral 论文
CVPR 2023| 基于上下文视觉学习的多功能模型
CVPR 2023|AI视频生成
CVPR 2023| Lite-Mono:轻量级自监督单目深度估计
CVPR 2023|基于动漫人物画像的风格化单视图3D重建
CVPR 2023|数字虚拟人生成
CVPR 2023|ScarceNet:动物姿态估计
CVPR 2023|HOLODIFFUSION 3D扩散模型
CVPR 2023|图像超分辨
CVPR 2023|时序动作检测
CVPR 2023|掩码图像建模
CVPR 2024 | 医学图像分割 | 高效多尺度卷积注意力解码器EMCAD
CVPR 2024 | 图像恢复 | Adaptive Sparse Transformer
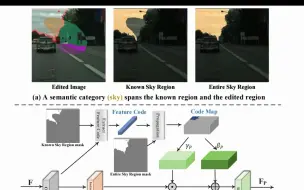
CVPR 2023|语义图像编辑
1分钟内快速完成学术润色,全网最简易论文润色教程来啦!
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
【CVPR'24】扩散模型中时间区间端点奇异性的解决
讲座 | 交互式3D世界生成——斯坦福大学博士生俞洪兴
一小时深度解析【Sora分析】视频生成模型,如何做到文本生成视频?详解背后的技术原理与应用案例!!!
AI 快速生成论文写作框架!
CVPR2023|通过帧间注意提取运动和外观用于视频帧插值
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!
OpenCV钢管计数实战,写进简历的工业级视觉项目!
深度学习最热方向!今年最全的多模态大模型综述来啦!-神经网络/大模型/LLM
研0和研1怎么快速找到论文代码并且复现模型代码?20分钟事无巨细的教会你!-深度学习/机器学习/神经网络
多模态模型+Sam2 CV视频物体处理 更上新台阶, Sam2会是多模态领域的Chatgpt吗?
Bi_direct_adapter(通用双向适配器)-来自AAAI2024!适用于多模态领域
【论文导读】视觉语言地学大模型综述(一)导论
耗时六个月,我造出了《三体》中机器人刺杀罗辑的KILLER病毒
太厉害了 已跪!终于有人能把OpenCV图像处理讲的这么通俗易懂了,现在计算机视觉opencv全套分享给大家。
讲座 | 面向多模态大模型的具身智能平台LEGENT——清华大学THUNLP lab在读博士胡锦毅
分享一个免费GPT站点,免梯直达官网,可使用全部功能
深度学习计算机视觉项目实战:基于OpenCV和YOLOV5的缺陷检测检测实战,原理详解+代码实战,看完就能跑通!
【论文导读】DiffusionSat:A generative foundation model for satellite imagery