V
主页
CVPR 2023|音频驱动共语手势生成
发布人
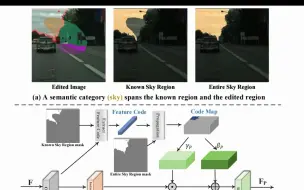
Taming Diffusion Models for Audio-Driven Co-Speech Gesture Generation paper: https://arxiv.org/pdf/2303.09119.pdf code: https://github.com/advocate99/diffgesture
打开封面
下载高清视频
观看高清视频
视频下载器
CVPR 2023|基于扩散模型的泛化音频驱动的肖像动画
CVPR2023|隐式扩散模型用于连续图像超分辨
CVPR 2023|SDFusion:多模态3D形状补全、重建和生成
CVPR 2023|生成辅助视频描述用于文本-视频检索
CVPR 2023|第一人称视角视频的3D手部姿势估计和动作识别
CVPR 2023|学习多模态扩散模型用于音视频生成
CVPR 2023|A2J-Transformer:3D交互手部姿态估计
CVPR 2023|布局到图像生成的可控扩散模型
CVPR 2023| Lite-Mono:轻量级自监督单目深度估计
CVPR 2023|AI视频生成
CVPR 2023|ScarceNet:动物姿态估计
CVPR 2023|T2M-GPT:基于离散表达从文本生成动作
InternVL作者详解CVPR Oral 论文
CVPR 2023|PoseFormerV2:利用频域信息改进3D人体姿态估计
CVPR 2023|颜色风格迁移
CVPR 2023|掩码图像建模
一小时深度解析【Sora分析】视频生成模型,如何做到文本生成视频?详解背后的技术原理与应用案例!!!
CVPR 2023|时序动作检测
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
AI 快速生成论文写作框架!
第一话的残留音频(只有一秒)
CVPR2023|通过帧间注意提取运动和外观用于视频帧插值
CVPR 2023|从演示视频到目标图像的功能性区域定位
CVPR 2023|双路适配图像到视频的Transformers
CVPR 2023|基于动漫人物画像的风格化单视图3D重建
CVPR 2023|基于文本的图像编辑
CVPR 2023|图像超分辨
2分钟内快速完成学术论文全文翻译
跨模态细粒度高清检索项目
1分钟内快速完成学术润色,全网最简易论文润色教程来啦!
超实用的AI 论文审稿,大部分期刊编辑都在抢着用!
【脑客中国·科研】第155位讲者 | 王杰:多模态磁共振成像与脑科学
现在是否是大语言模型的垃圾时间?
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!
CVPR 2023|语义图像编辑
任意文献PDF内容,30秒自动生成思维导图,助力科研学习每一天!
AAAI2025投稿教程,或许只有在deadline前没有来得及把模版改完,错过了投稿,才会深刻的学会如何换模版?
【恋与深空】【秦彻&你】音频/车/香甜的cake就该由fork来品尝。(上车注意带好耳机)
标星57.2K,近百万研究生收藏的逐行代码解读网站!后续有惊喜 不看完一定后悔 (sci论文,cvpr,顶会顶刊)
【论文导读】DiffusionSat:A generative foundation model for satellite imagery