V
主页
京东 11.11 红包
深度篇:谷歌“万能”语音识别大模型USM全面碾压了OpenAI的Whisper模型
发布人
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages Abstract: We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages. #google #usm #asr #openai #whisper #multimodal #multilingual #speech #seamlessm4t #voicebox == Olewave offers avant-garde bespoke solutions for proprietary data labeling, normalization, and transformation. Tired of inaccurate transcriptions and frustrating APIs? Olewave offers a superior solution with: • AI-powered Accuracy: Transcribe any audio, regardless of language, dialect, accent, or topic, with exceptional accuracy. We surpass the competition in understanding even the most challenging recordings. • Detailed Insights: • Privacy Guaranteed: • Competitive Pricing: Ready to experience the difference? Don't settle for mediocrity. Contact info@olewave.com and give us a try! Customized Large-Scale Datasets Olewave delivers customized, labeled, and validated large-scale real-world NLP/CV/speech/multimodal datasets of various scenarios such as dictation and conversation in multi accents/dialects/languages, and of diverse topics such as education, finance, legal, entertainment, healthcare, retail, and customer service.
打开封面
下载高清视频
观看高清视频
视频下载器
Whisper终结者:Reverb ASR 语音识别和说话人分离方面新标杆 在前所未有的20万小时人工转录数据上进行训练 支持可定制的逐字转录
十分钟告诉你为什么OpenAI的Whisper语音识别没ChatGPT那么好用 [语音语言论文阅读]
2024最火的两个模型:Informer+LSTM两大时间序列预测模型,论文精读+代码复现,通俗易懂!——人工智能|AI|机器学习|深度学习
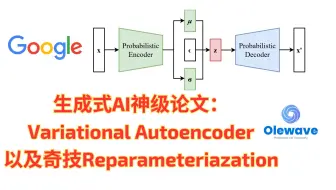
生成式AI神级论文:谷歌DeepMind的Variational Autoencoder (VAE) and Reparameterization
谷歌能打开了???(没挂梯子)
基于faster_whisper的实时语音识别 | 可对接大模型的实时语音识别 | 实时语音识别 | 一句话识别
太厉害了!终于有人能把OpenCV图像处理+YOLO目标检测讲的这么通俗易懂了!无偿分享学不会你来找我!_计算机视觉/深度学习/OpenCV/YOLO
从OpenAI's Whisper模型到你自主研发的语音识别服务: 后处理与语言模型 (第四部分)
语音文本技术论文阅读 OpenAI最新的Whisper ASR也会像GPT-3一样火起来吗?
AI一键音频转文字、音频转字幕工具,视频生成字幕、语音转文本,OpenAI开源语音识别神器Whisper本地一键整合包下载
十分钟看懂脸书太极拳法Wav2Vec2.0 -- 语音预训练模型就像绝命毒师老白教杰西
从OpenAI's Whisper模型到你自主研发的语音识别服务: 投产比 (第二部分)
【比看狂飙还爽!】2024年最全人工智能入门的天花板教程!不接受任何反驳,草履虫都能学会!人工智能|AI|机器学习|深度学习|)
详解语音合成中的Hifi-GAN
基于faster_whisper的实时语音识别改进版 | whisper中出现繁体中文的解决方法 | 语音识别中繁体转简体 | OpenCC
第十六课ASRPRO配置模式PWM输出和电机控制
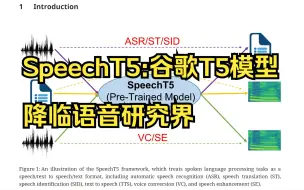
详解SpeechT5: 将谷歌T5模型引入语音领域
谷歌的时间机器与人工智能「无片尾」
2024年诺贝尔物理学奖得主杰弗里·辛顿珍贵访谈:他发明了AI,但又最警惕AI
[Long Review] 用GShard训练超级大AI模型:GShard: Scaling Giant Models
语音识别转文字软件faster-whisper整合包下载,免费语音转文字工具
冒失上传!跨境电商必备!【Google ads谷歌广告全类型投放教程】Shopify独立站
读研期间,如何快速学会语音识别技术?多亏了这套NLP语音识别项目全套教程!从零基础到实战简单明了讲明白了!语音分离、语音合成、变声器
Transformer模型原理解读:Swin、VIT、DETR、BERT四大Transformer核心模型一口气学到爽!(深度学习/计算机视觉)
【精华30分钟】字节大佬终于把AI Agent讲清楚了!通俗易懂,2024最新内部版,学完即就业!拿走不谢,允许白嫖,学不会我退出IT圈!
我实现了语音流式转录翻译!(win11实时字幕+Luna Translator hook)
最新OpenAI+Microsoft, Google, Meta, and Nvidia开源语音大模型评价:语音识别部分
程序员必看的数学知识!一本小册子就能吃透线性代数!这本书你一定不能错过!真的通俗易懂!(微积分、核函数变换、随机变量、概率论基础、泰勒公式与拉格朗日)
【全集188集】深度学习必看圣经!李沐大神《动手学深度学习》最新版全套视频教程分享,比啃书高效!看完直接跑通!(深度学习/神经网络/计算机视觉)
比刷剧还爽!2024最新Python金融分析与量化交易实战教程!三小时入门到进阶!就怕你不学!(AI人工智能丨数据分析丨数据挖掘丨机器学习实战丨深度学习丨编程)
谷歌首席「预言家」惊爆:2029年人类将实现永生!男女关系变的微妙,「远程性爱」将被实现!
深度篇:Apple的新MM1是否是地表最强多模态大模型?
十分钟看懂谷歌易筋经BERT
2024年9月华为手机鸿蒙系统3.04.04.2最新版安装谷歌服务框架GMS谷歌商店谷歌三件套华为P60 P50 P70 Mate60Mate70
Gemini 1.5 模型更新解析:Pro vs Flash,多模态能力展示及提示工程技巧
刚刚被公布OpenAI CEO Sam Altman 五月在哈佛大学商学院的一段访谈,还是有很多爆料
详解Google经典的SoundStream: the Neural Audio Codec
详解OpenAI GPT-3: Language Models are Few-Shot Learners(2/3)
Meta刚刚发布了一个令人恐惧的AI模型,可以创建带声音的视频