V
主页
详解OpenAI GPT-3: Language Models are Few-Shot Learners(2/3)
发布人
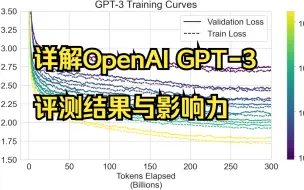
Language Models are Few-Shot Learners Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general. #openai #chatgptplus #chatgpt #pretrain #gpt3 #review #nlp #ethicalai #llm #bert #coursera #ml #course #rl #rewardmodel #ppo #instructgpt #sota #imagenet #inanutshell
打开封面
下载高清视频
观看高清视频
视频下载器
详解AudioLM: a Language Modeling Approach to Audio Generation
从入门到提示词工程师:全网最通俗易懂Prompt-Learning提示词学习教程!草履虫都学的会!
生成式AI神级论文:谷歌DeepMind的Variational Autoencoder (VAE) and Reparameterization
[Long Review] Axial Attention in Multidimensional Transformers
详解微软零样本语音合成VALL-E
击败OpenAI GPT-4的Claude 3有什么秘密武器?Opus, Sonnet, and Haiku Models, Constitutional AI
[Long Review] Cascaded Diffusion Models for High Fidelity Image Generation
深度篇:谷歌“万能”语音识别大模型USM全面碾压了OpenAI的Whisper模型
详解OpenAI GPT-3: Language Models are Few-Shot Learners(3/3)
语音NLP论文阅读 Token-level Sequence Labeling for SLU using Compositional E2E Models
[独家解密] 大神杨立昆新出的'语音魔盒'会让语音算法工程师失业吗(Meta AI's VoiceBox)
深度学习缝了别人的模块,创新点如何描述?附魔改注意力机制+多尺度特征融合模块源码
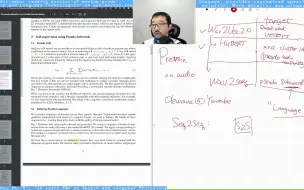
详解OpenAI GPT-3: Language Models are Few-Shot Learners(1/3)
十分钟看懂脸书太极拳法Wav2Vec2.0 -- 语音预训练模型就像绝命毒师老白教杰西
[Long Review] Conformer: Convolution-augmented Transformer for Speech Recogniti
语音文本技术论文阅读 Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recogni
十分钟看懂脸书虎爪绝户手 - 虎BERT - HuBERT: Self-Supervised Speech Representation Learning
语音文本技术论文阅读 OpenAI最新的Whisper ASR也会像GPT-3一样火起来吗?
[Long Review]Switch Transformers: Scaling to Trillion Parameter Models with
语音文本技术论文阅读 Scaling Laws for Neural Language Models
三分钟搞定ChatGPT
[Long Review] GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
[Long Review]Kullback-Leibler Divergence: Listen, Attend, Spell and Adapt ASR
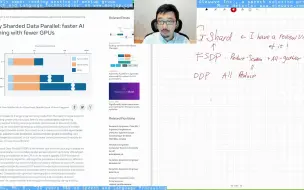
[Long Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs
太厉害了 已跪!终于有人能把知识图谱讲的这么通俗易懂了,浙大知识图谱入门及实战公开课分享!-深度学习丨NLP丨知识图谱
从OpenAI's Whisper模型到你自主研发的语音识别服务: 长音频与流式识别 (第三部分)
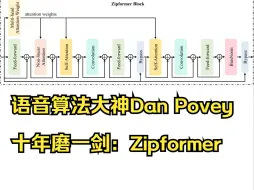
[论文阅读] Zipformer: A faster and better encoder for automatic sp
十分钟看懂谷歌W2v-BERT: Combining Contrastive Learning and Masked Language Modeling
分析2023最新的OpenAI的GPT-4技术报告
入门KG必看!迪哥通俗易懂的讲解知识图谱核心知识及项目实战,带你手撕Neo4j图数据、医疗智能问答助手、NLP关系抽取核心技术等实战源码!
[Short Review]Conformer Convolution-augmented Transformer for Speech Recognition
[Long Review] CLAS: Deep context: end-to-end contextual speech recognition
详解语音合成中的Hifi-GAN
[Long Review] Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using
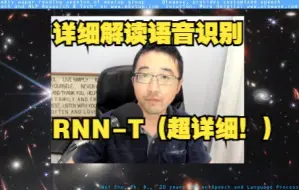
语音文本技术论文阅读 RNN-T: Sequence Transduction with Recurrent Neural Networks
详解I-JEPA: 杨立昆大神用第一个'世界模型'降维打击计算机视觉圈
语音文本技术论文阅读 Joint Unsupervised and Supervised Training for Multilingual ASR
十分钟看懂微软大力金刚掌WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack
【深度学习零基础篇】从入门到精通一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络!
语音文本技术论文阅读 One-Edit-Distance Network (OEDN) in Mispronunciation Detection & ASR