V
主页
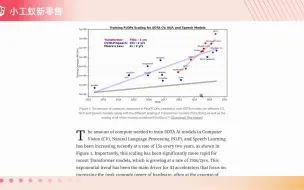
AWQ大模型量化INT4比FP16 推理快2倍,GPU内存1/3
发布人
AWQ大模型量化INT4比FP16 推理快2倍,GPU内存1/3
打开封面
下载高清视频
观看高清视频
视频下载器
用GPTQ算法量化大型模型 大幅减少GPU使用并提高准确率
llama.cpp大神实现投机采样,让大模型推理性能直接翻倍 #小工蚁
大模型量化技术概述
Qwen1.5系列6个模型如何选择? AWQ还是GPTQ?#小工蚁
Transformers支持3种量化算法性能对比 #小工蚁
几百次大模型LoRA和QLoRA 微调实践的经验分享
Embedding模型8bit量化推理 成本下降4倍,准确度下降0.7%
不看太可惜!又快又准,即插即用!Sage Attention——清华8bit量化Attention
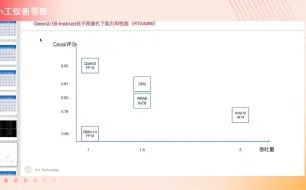
Qwen2-7B-Instruct不同量化方法准确度和性能比较
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
多GPU推理加速Qwen-72B开源大模型 #小工蚁
阿里发布Text2SQL最新实践开源模型准确度超GPT4
LLM部署在生产环境优化(1/3)模型量化
Liger Kernel开源加速大模型训练 算子,降低60%GPU显存
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
大模型推理性能优化策略 #小工蚁
如何让清华ChatGLM2-6b模型推理性能提升20倍? #小工蚁 #chatglm2
清华智谱开源视觉大模型 CogVLM,可免费商用
将LLaMA3上下文长度从8K扩展 到超过100万
斯坦福博士开源新算法FlashAttention2 让Transformer模型推理和训练成本再削50%
为什么说AI芯片的最大问题不是算力,而是内存带宽? #小工蚁 #英伟达
借助Redis存储缓存KV大幅降低大模型推理TTFT
用世界最大GPU训练性能出众btlm-3B-8k开源小模型 #小工蚁
从 SAM 到 FastSAM:中科院团队成功实现通用视觉模型速度革命
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
谷歌发现RAG缩放定律 释放LLM长上下文潜力 提升RAG准确率 #小工蚁
如何消除大模型幻觉? 提高准确率 LoRA+MoE
如何提高垂直领域RAG准确率? #小工蚁
StreamingLLM算法让推理速度 提升22倍,支持400万Token输出
WebGLM:高效网络增强型问答系统,清华开源模型
探索Falcon模型:构建推理、量化和微调的高效语言模型
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
大模型微调训练实践 准确度10%提升至90%
训练大语言模型LLM 如何定义自己训练数据集?#小工蚁
清华发布SmartMoE一种高效训练专家模型网络算法 #小工蚁 #清华 #MoE
矢量数据库对比和选择指南
多专家提示工程MEP 提高大模型回答准确率
LLM如何接入到个人微信? 演示群聊中AI自动回复
Vanna开源Text to SQL项目