V
主页
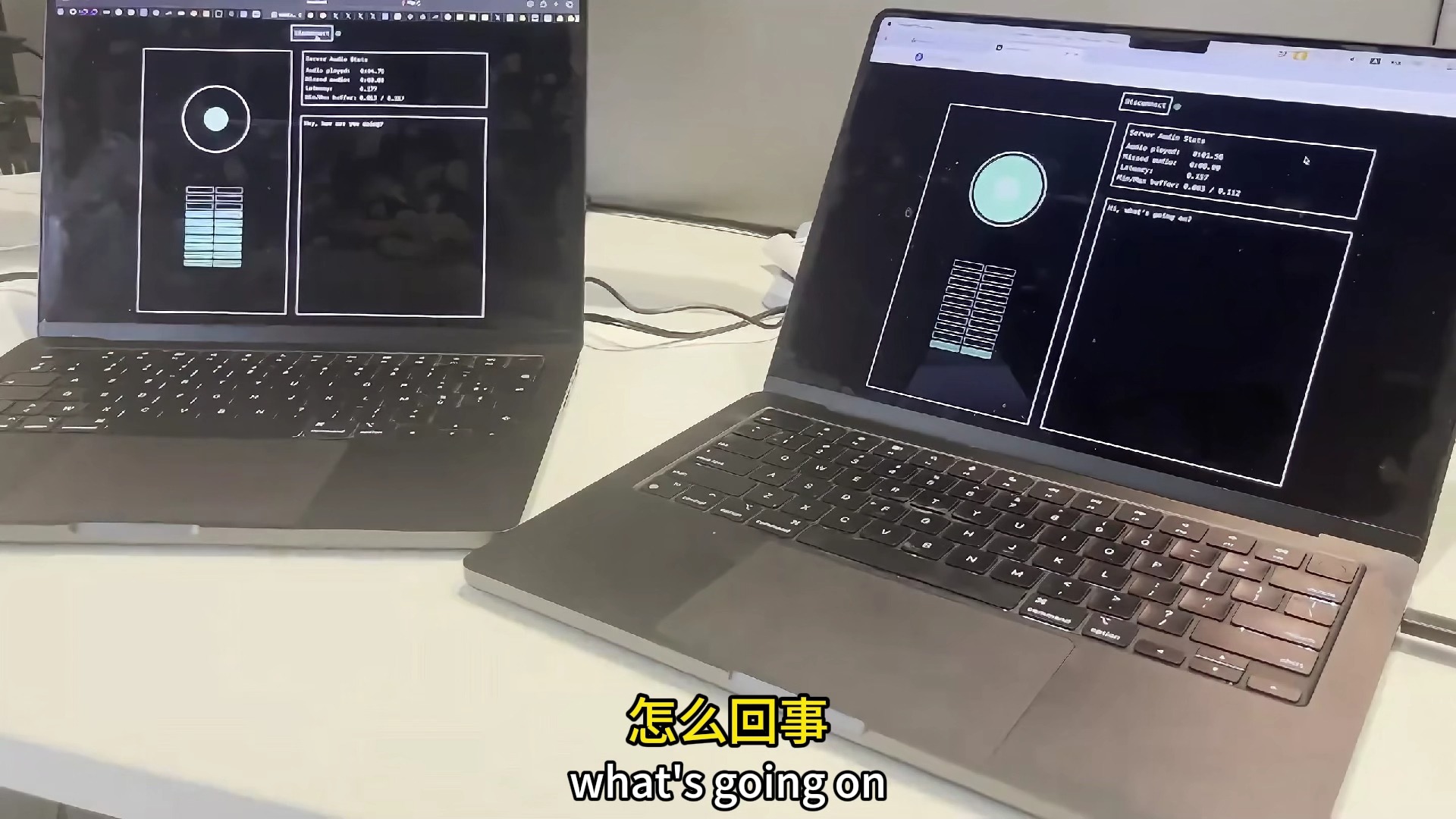
Kyutai于2024年9月18日开源了其7月份友巴黎发布的Moshi AI语音助手,仅7B参数量,延迟200毫秒,比肩GPT-4o的实时对话体验
发布人
Kyutai 研究实验室2024年7月4日在巴黎发布了 Moshi AI语音助手(并于2024年9月18日开源第一个版本) 今天他们终于正式发布了一份包含模型所有细节的长篇技术报告、Moshi 及其 Mimi 编解码器的权重,以及在 Pytorch、Rust 和 MLX 中的流式推理代码. 实时对话的语音-文本基础模型:实时全双工口语大语言模型,理论延迟为 160 毫秒,实际延迟为 200 毫秒 采用多流架构,能够同时处理用户和系统的语音输入,并生成相应的语音输出。 能够同时处理语音和文本信息,支持复杂的对话动态,包括同时说话和打断。 支持实时流式推理,能够在生成语音的同时进行语音识别和文本到语音的转换。 发布的模型有两个版本,一个男性和一个女性声音。 技术报告分析:Moshi由三个主要部分组成:Helium、Mimi以及一个新的多流架构 Helium 7B参数的语言模型:Helium是一个基于Transformer架构的自回归语言模型,经过2.1万亿个token的预训练。 高质量的文本数据:使用高质量的数据源(如Wikipedia、Stack Exchange等)以及CommonCrawl的网络爬取数据进行训练。 优化和架构调整:包括使用RMS归一化、旋转位置嵌入(RoPE)、FlashAttention等技术来提高训练效率和模型性能。 Mimi 神经音频编解码器:Mimi通过残差向量量化(RVQ)和知识蒸馏技术,将音频转换为离散的token,同时建模语义和声学信息。 性能优势:与现有的SpeechTokenizer、RVQGAN和SemantiCodec等技术相比,Mimi在语义和声学性能上都有显著提升。 为LLMs设计:Mimi特别为与大型语言模型(LLMs)配合使用而设计,以12.5Hz和1.1kbps的速率运行,完全因果关系,适合流式Transformer。 多流架构 RQ-Transformer:这是一种用于离散图像生成的架构变体,允许在不增加Helium(Temporal Transformer)序列长度的情况下,通过使用较小的Depth Transformer来建模语义和声学token的层次结构。 实时性能:只需通过7B参数的Helium模型12.5次,即可实时处理1秒的音频,即使是在L4或M3 MacBook Pro上也能实现。 内心独白 (Inner Monologue): 一种通过预测 Moshi 语音对应文本的方式,显著提高生成语音质量和连贯性的方法。 有趣的副产品 流式TTS和ASR:通过延迟音频token几秒钟,可以得到流式TTS系统;相反,通过延迟文本token,可以得到流式ASR和对齐。 在线体验:https://www.moshi.chat Github:https://github.com/kyutai-labs/moshi 抱脸模型仓库:https://huggingface.co/collections/kyutai/moshi-v01-release-66eaeaf3302bef6bd9ad7acd 技术报告:https://kyutai.org/Moshi.pdf Kyutai是一个致力于AI开放研究的非营利实验室,由Iliad集团、CMA CGM和Schmidt Sciences于2023年11月成立。初创团队由六名顶级科学家组成,他们都曾在美国的大型科技实验室工作。Kyutai继续招聘顶级人才,还为研究硕士学位学生提供实习机会。现在该团队已有12名成员,并将在年底启动首批博士论文研究。研究探索新的一般用途模型,具备高能力。实验室目前特别研究多模态模型,即模型能够利用不同类型的内容(文本、声音、图像等)进行学习和推理。所有开发的模型、软件和实现其创建的技术知识都将免费分享。为开展工作和训练模型,Kyutai特别依赖Iliad集团子公司Scaleway提供的Nabu 23超算节点。
打开封面
下载高清视频
观看高清视频
视频下载器
GameGen-X:生成可交互式开放世界视频游戏的Transformer模型[完蛋,以后世界真有可能是实时生成的][AI生成类“黑神话”游戏视频]
Loopy:字节新论文通过音频驱动静态照片生成动态视频,并能生成极自然动作,表情变化、头部移动等,效果远超Hallo、EchoMimic等开源项目
Spectacles:Snap发布第五代Spectacles AR眼镜,能在几秒钟内根据语音提示生成3D小动画,内置基于OpenAI的聊天机器人"My AI"
海螺视频更新推出图生视频能力,MiniMax旗下海螺AI推出的视频生成模型实力不错,提示词遵循能力较强,能与可灵、Gen-3、Lunma一战
[以后游戏真的可以实时生成和修改了]EA即将推出AI游戏生成系统,打字就能实时生成游戏场景、角色、改变规则
[AI还能生成这个?]利用Luma Dream Machine的首尾帧功能+AE制作震撼的「全景动态运镜视频」
Teledraw:语音实时绘画生图,借助GPT-4o高级语音API对接生图模型达成的“用嘴画图”
24秒的AI视频短片,AI视频角色一致性已再次进步
ReadTheirLips:用AI读懂唇语!上传任何人物讲话的视频,模型将能识别他们说了什么
MagicQuill:蚂蚁开源一个实现精确图像编辑的智能交互系统(支持精确画笔+提示词编辑体验)[魔法画笔]
PersonaTalk:字节新论文,可通过参考视频和目标音频创建唇形同步的可视化配音,同时保留说话风格和面部细节
Jack-AI-青花瓷(自录音训练RVC模型翻唱)科技进步太快了,可能以后AI唱歌比你自己更强
HeyGen推出Avatar 3.0:已经超越了简单的唇形同步,具备了全身动态运动能力,能模拟更真实自然的情绪
Codia AI Design:Codia AI 推出的Figma的付费插件,将截图转为可编辑的Figma设计稿 [截图转设计稿]
Molmo:基于Qwen2-72B再训练的一系列开源多模态模型,在人工评估中排名第二,仅略低于 GPT-4o [完全开源]
Voice Agent API:Deepgram推出了全新的AI语音代理API,能够进行实时自然的语音对话
Follow-Your-Canvas:竖屏秒变横屏,腾讯&清华提出扩展视频的方法,补充画面无缝衔接
Jack-AI-浮夸(自录音训练RVC模型翻唱的陈奕迅-浮夸)科技进步太快了,可能以后AI唱歌比你自己更强
鸿蒙NEXT小艺太强了,又让我涨见识了~
突破个人能力天花板,和AI协作的12个范式。
Avatar3.0 with Unlimited Looks:HeyGen升级了Avatar功能,能生成穿着不同衣服、不同姿势和相机角度的 AI 口播视频
Pika“失联”半年之久终于发布了v1.5版本,真正做到让视频生成低门槛、有趣、好玩
X- Portrait2:字节新论文可将任意视频角色的表情和动作转移到任意对象,效果超过了Runway Act-One
TANGO:根据提供的语音和人物参考视频,自动生成让人物在视频里配合语音做出手势动作的新视频
In-video Text Translate:HeyGen升级了视频翻译功能,推出视频内文本翻译功能,不仅能翻译视频的配音,还能翻译视频画面中的文字
Jack-AI-王妃(自录音训练RVC模型翻唱)科技进步太快了,可能以后AI唱歌比你自己更强
Video to Video:Runway为Gen-3 Alpha推出“视频转视频”功能,现已面向所有付费用户开放[轻松改变视频风格]
Jack-AI-壁上观 | 科技进步太快了,以后AI唱歌比你自己更强【自录音训练唱腔RVC翻唱实验成功】
【黑科技】找到曾经删掉的所有qq空间说说、留言、以及照片!太离谱了...
Seed-Music:字节新论文提出高质量和可控音乐生成统一框架,音乐生成模型 支持多种数据输入生成和编辑音乐
Vidu 1.5:经网友测试v1.5的Vidu在2D动漫风格图片生成视频上的表现非常强
【苏星河短评】全网都在吹的手机AI,可能根本不是给你用的?
《迁徙》(Migration):Runway与导演 Jeremy Higgins,合作了一个很高水平的动画短片
【苏星河】鸿蒙Next到底好用吗?纯血鸿蒙全面体验!
《开口吧,人生》
【苏星河】苹果新的抄袭对象?让贾维斯成真的国产系统!
我们解开了HarmonyOS NEXT丝滑动画的秘密!【差评君】