V
主页
6-10Spark SQL四大目标
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
2-3Spark分布式计算流程中的几个疑问点
6-17Spark SQL未来会成为Spark的新核心
1-7Spark模块学习说明
1-2spark源代码环境的搭建
2-1Spark是怎么进行分布式计算的?
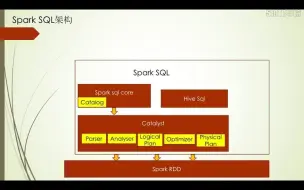
6-11Spark SQL架构及其处理流
2-3Spark Streaming Application原理
1-4Spark集群环境的搭建
13Spark SQL本地调试读写Hive
1-2spark源代码环境的搭建
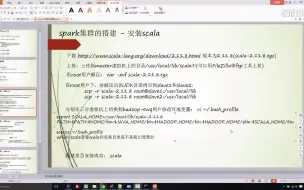
1-3Spark集群安装-虚拟机上Scala的安装
6-13DataFrame
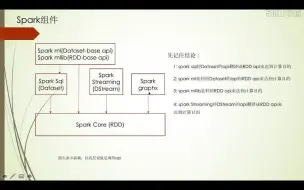
2-12Spark Graphx组件解决的问题及其特点
2-8Spark Core组件解决的问题及其特点
2-11Spark Streaming组件解决的问题及其特点
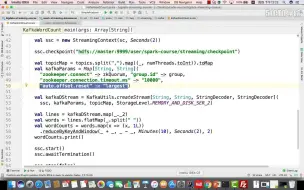
4-15Spark Streaming 集成 Kafka二
2-13Spark ml组件解决的问题及其特点
4-17spark-daemon脚本原理以及实现
7-3SparkSession的讲解
9通过beeline访问Spark SQL
6-3HBaseContext封装Spark和HBase交互的代码
4-7Spark Streaming集成Flume(pull模式)
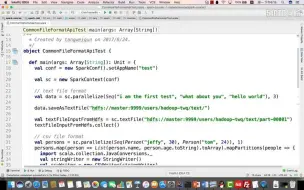
3-45spark支持的通用的文件格式
7-21DQL-sql查询及其sql函数讲解
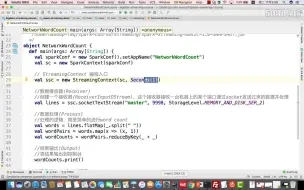
1-2实战:本地运行Spark Streaming程序
4-14利用SparkLauncher在代码中提交spark应用
4-14Spark Streaming 集成 Kafka一
10_sscanf高级用法
6-5Spark使用bulkput将数据写入到HBase中优化
6-14集合排序中使用隐式参数
3-43spark支持的读写存储系统
3-8Spark Streaming容错语义
4-6Spark Streaming集成Flume(push模式)
02_strcpy
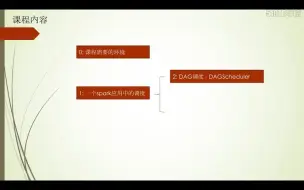
5-1课程内容
6-16Dataset API分类
1-27Federation配置
3-20parquet文件的读写(必须掌握)
4-1课程内容
1-5namespace