V
主页
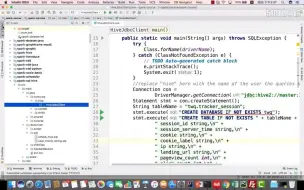
2-3Spark Streaming Application原理
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
1-2spark源代码环境的搭建
1-23Spark Streaming结合Spark Sql
1-4监控Spark Streaming程序
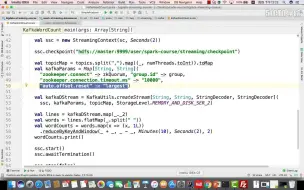
4-14Spark Streaming 集成 Kafka一
1-5集群spark-submit提交应用
4-18SparkSubmit原理以及源码分析
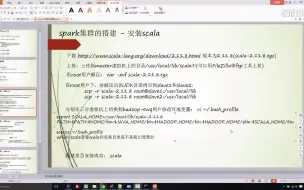
1-3Spark集群安装-虚拟机上Scala的安装
3-8Spark Streaming容错语义
1-7Spark模块学习说明
1-5讲解StreamingContext
6-4Spark使用bulkput将数据写入到HBase中
1-2实战:本地运行Spark Streaming程序
1-4Spark集群环境的搭建
2-9Spark SQL组件解决的问题及其特点一
2-7理解Spark分布式内存计算的含义
6-10Spark SQL四大目标
6-3HBaseContext封装Spark和HBase交互的代码
3-33union的使用及其原理.mkv
11Spark SQL代码中写SQL读写Hive
13Spark SQL本地调试读写Hive
3-7RangePartitioner的原理
1-24Spark Streaming进行网站流量实时监控
2-13Spark ml组件解决的问题及其特点
17Spark SQL和Hive的各自职责
4-14利用SparkLauncher在代码中提交spark应用
6-15Spark RDD中使用隐式转换
2-3WAL
4-17Java版本的Spark streaming集成Kafka
4-13python spark应用的正确提交
1-1核心原理课程内容
10通过JDBC访问Spark SQL
7-2浅尝spark SQL的API
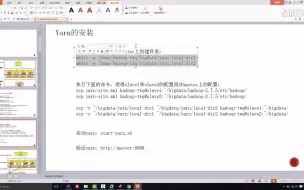
3-3Yarn的安装
10_sscanf高级用法
6-5Spark使用bulkput将数据写入到HBase中优化
1-3Scala的诞生史
3-28通过原理图和源代码详解cogroup原理
3-39checkpoint实现原理一
3-19RDD的pipe的原理深入讲解
1-21读HDFS文件实战与原理讲解