V
主页
[Long Review] Conformer: Convolution-augmented Transformer for Speech Recogniti
发布人
Join 'Speech and Language Technologies' Meetup group https://www.meetup.com/speech-and-language-technology-meetup-group/ to see weekly paper reading schedules and discussions. Conformer: Convolution-augmented Transformer for Speech Recognition Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, Ruoming Pang Download PDF Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
打开封面
下载高清视频
观看高清视频
视频下载器
生成式AI神级论文:谷歌DeepMind的Variational Autoencoder (VAE) and Reparameterization
十分钟看懂脸书太极拳法Wav2Vec2.0 -- 语音预训练模型就像绝命毒师老白教杰西
[Long Review] Axial Attention in Multidimensional Transformers
语音文本技术论文阅读 OpenAI最新的Whisper ASR也会像GPT-3一样火起来吗?
语音NLP论文阅读 Token-level Sequence Labeling for SLU using Compositional E2E Models
[Long Review] GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
语音文本技术论文阅读 Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recogni
谷歌大神科学家独家深度揭秘端到端自动语音识别算法与系统, [第一部分]:总述与建模
详解微软零样本语音合成VALL-E
详解AudioLM: a Language Modeling Approach to Audio Generation
击败OpenAI GPT-4的Claude 3有什么秘密武器?Opus, Sonnet, and Haiku Models, Constitutional AI
从OpenAI's Whisper模型到你自主研发的语音识别服务: 长音频与流式识别 (第三部分)
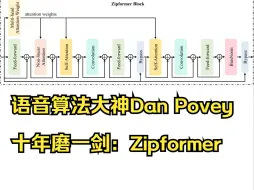
[论文阅读] Zipformer: A faster and better encoder for automatic sp
[Short Review]Conformer Convolution-augmented Transformer for Speech Recognition
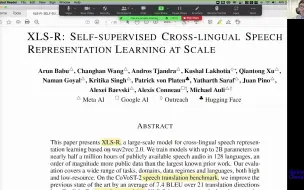
语音文本技术论文阅读 XLS-R: Self-supervised Cross-lingual Speech Representation Learning a
语音文本技术论文阅读 Scaling Laws for Neural Language Models
[Long Review] CLAS: Deep context: end-to-end contextual speech recognition
[Long Review]Kullback-Leibler Divergence: Listen, Attend, Spell and Adapt ASR
[Long Review] Xception: Deep Learning with Depthwise Separable Convolution
[Long Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs
三分钟搞定ChatGPT
语音文本技术论文阅读 One-Edit-Distance Network (OEDN) in Mispronunciation Detection & ASR
独家揭秘OpenAI GPT-4o逆天网络结构,居然高中生也能看懂
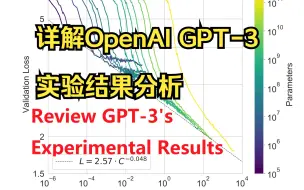
详解OpenAI GPT-3: Language Models are Few-Shot Learners(2/3)
深度篇:Apple的新MM1是否是地表最强多模态大模型?
Xmart • 前沿讲座 | 【李宏毅】将新技能教给基础模型的挑战
必读:生成式AI Sora相关的Normalizing Flows
还是太全面了!NLP十天起飞,一口气学完文本分类、文本摘要、机器翻译、知识图谱、情感分析等十大技术点!算法原理+论文解读,草履虫都能学会!大模型|机器学习
语音文本技术论文阅读 RefineGAN - Universally Generating Waveform Better than Ground ...
语音文本技术论文阅读 Branchformer: Parallel MLP-Attention Architectures and E-Branchformer
最新OpenAI+Microsoft, Google, Meta, and Nvidia开源语音大模型评价:语音识别部分
零基础小白三个月成为AI算法工程师,保姆级学习路线图! ---人工智能/深度学习/机器学习/AI算法工程师
[Short Review] Transfer Learning from Speaker Verification to Multispeaker TTS
十分钟看懂谷歌易筋经BERT
详解OpenAI GPT-3: Language Models are Few-Shot Learners(1/3)
解锁天顶星科技ChatGPT
【斯坦福吴恩达】2024公认的最好的扩散模型原理课程-How Diffusion Models Work~
[Short Review] Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using
[Short Review] Deduplicating Training Data Makes Language Models Better
开场白