V
主页
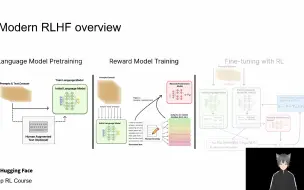
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
发布人
本期 code https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/trl_hf/trl_dpo.ipynb https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/trl_hf/dpo_math.ipynb trpo:BV1hD421K7gG ppo:BV11J4m137fY PPOTrainer(TRL):BV1ss421G7Nj trl Reward model:BV1GZ421t7oU
打开封面
下载高清视频
观看高清视频
视频下载器
全网最通俗易懂,大模型偏好对齐RLHF从PPO推导DPO再推导simPO
大模型RLHF从PPO推导DPO再推导SimPO,公式推导
【LibrAI | 智衡 阅读会】第一期:DPO与PPO之争,谁才是RLHF的通解?
ChatGPT狂飙:强化学习RLHF与PPO!【ChatGPT】原理第02篇
PPO算法
DPO V.S. RLHF 模型微调
14大模型全栈-强化学习07-DPO原理公式推导
【大模型+强化学习】怎么理解大模型训练中的RLHF(人类反馈强化学习)?ChatGPT背后的数学原理
基于TRL训练大预言模型,DPO,PPO方法.
代码实现大模型强化学习(PPO),看这个视频就够了。
DPO算法详解 : Direct Preference Optimization 算法详解 (RLHF的替代算法)
PPO@RLHF ChatGPT原理解析
13大模型全栈-强化学习06-DPO流程、代码以及损失函数介绍
第十课:RLHF
大模型成功背后的RLHF到底是什么?
【李宏毅2024春最新】第8讲 生成式AI导论(中文)RLHF 大预言模型修炼史(3) by Hung-yi Lee
吴恩达《从人类反馈中进行强化学习RLHF, Reinforcement Learning from Human Feedback》(中英字幕)
4..DPO训练为什么内容会变长,DPO内容冗余
近端策略优化(PPO)深入实践
【通义千问2.0】微调之DPO训练
不愧是李宏毅老师讲的【强化学习】简直太详细!!!导师不教你的,李宏毅老师亲自教你,这还不赶紧学起来!!!-人工智能/强化算法/机器学习
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
ChatGPT和PPO(中文介绍)
零基础学习强化学习算法:ppo
用RLHF的方法解读论语
11大模型全栈-强化学习04-RLHF实战-deepspeed-chat实战
构建大语言模型,DPO训练方法,原理和实现
DPO:人类偏好对齐技术——大模型训练的最后一公里
深度强化学习 PPO 纯白板逐行代码Python实现
大语言模型RLHF算法PPO讲解
[personal chatgpt] trl 基础介绍:reward model,ppotrainer
RLHF大模型加强学习机制原理介绍
DPO (Direct Preference Optimization) 算法讲解
大模型训练:Direct Preference Optimization (DPO) explained Bradley-Terry model
手写一个llama factory—10-DPO训练操作方式
RLHF训练法从零复现,代码实战,大语言模型训练
Llama3模型,从零构件复现,使用RLHF方法训练.代码实战.
Policy Optimization & TRPO & PPO | RL原理讲解系列#3
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
大语言模型LLM第三集:RLHF