V
主页
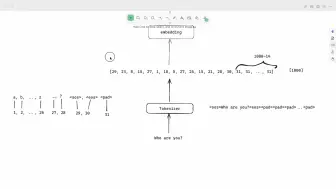
【研1基本功 (真的很简单)Encoder Embedding】手写编码模块、构建Encoder Layer
发布人
先看文档 先看文档 https://dwexzknzsh8.feishu.cn/docx/VkYud3H0zoDTrrxNX5lce0S4nDh?from=from_copylink
打开封面
下载高清视频
观看高清视频
视频下载器
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)
【研1基本功 别人不教的,那就我来】SSH+Git+Gitee+Vscode 学会了就是代码管理大师
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
4.什么是Embedding
【汇报】 时间序列预测 阶段学习总结 (Transformer,CNN,RNN,GNN)
【Transformer模型】曼妙动画轻松学,形象比喻贼好记
transformer原理与实现(自己梳理过的所以就发出来了Orz)
ICLR2023--SeaFormer:轻量高效的注意力模块
【研1基本功 (真的很简单)Decoder Encoder】手写Decoder Layer 准备召唤Transformer
五分钟图解embedding
【深度学习基本功!启动!】带你手敲Transformer代码之-Embedding篇!-神经网络/pytorch深度学习
师傅,我真的悟了!Visual Transformer代码从头写一遍~
【研1基本功 (真的很简单)Diffusion Vision Transformer (DiT)】构建DiT核心代码
白话transformer(一)_注意力机制
深度学习模块缝合以及如何找模块的一些心得
09 Transformer 之什么是注意力机制(Attention)
简单讲解注意力机制(Attention Mechanism)原理 + 多头注意力代码实现
全网最透彻的注意力机制的通俗原理与本质【推荐】
超强动画,一步一步深入浅出解释Transformer原理!
Attention机制(大白话系列)
准研一,导师让学习pytroch,之前没接触过机器学习,是直接学pytorch还是先学机器学习?有没有一份适合于专科、本科、硕博生的人工智能学习路线!
【官方双语】Transformer模型最通俗易懂的讲解,零基础也能听懂!
Attention机制 Encoder-Decoder框架简要讲解
以U-Net为例,缝合模块教程,深度学习通用,看完不会直接来扇UP,报销路费
『教程』一看就懂!Github基础教程
【深度学习缝合模块】废材研究生自救指南!12个最新模块缝合模块创新!-CV、注意力机制、SE模块
从0开始训练1.4b中文大模型的经验分享
【研1基本功 (真的很简单)LoRA 低秩微调】大模型微调基本方法1 —— bonus "Focal loss"
14 分钟解释所有学习算法
研究生须知:要基于pytorch做深度学习,但是我代码水平很低,我应该如何学习呢?
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
吹爆!2024最详细的大模型学习路线整理出来啦!迪哥手把手教你最高效的大模型学习方法,轻松搞定AIGC大模型!(大模型训练/大模型微调)
Transformer论文逐段精读【论文精读】
【研1基本功 (真的很简单)Diffusion Model】完成扩散模型!!结尾有bonus!!
深度学习研一小白水一篇论文流程
Transformer 的 Pytorch 代码实现讲解
强烈推荐!台大李宏毅自注意力机制和Transformer详解!
Transformer代码(源码Pytorch版本)从零解读(Pytorch版本)
24年最好发论文的方向:Mamba魔改&应用,24篇参考文献来袭!