V
主页
Spark MLLib 电影聚类分析Scala (Spark实验三)
发布人
利用Spark MLLib库进行电影聚类分析(Scala语言)
打开封面
下载高清视频
观看高清视频
视频下载器
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第1小节 项目介绍
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第7小节 可视化系统
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第8小节 可视化大屏
【七天做完大数据毕设】基于Hadoop、Hive和Spark的豆瓣电影可视化分析系统 第1小节 项目介绍
决策树 ID3 计算实例
DBSCAN聚类的python实现( iris数据集)不同聚类算法实验对比(moons,blobs,circle数据集)
基于密度的聚类 DBSCAN 解释与实例计算
实验十一 spark RDD基本操作命令实践
实验十 spark submit shell操作命令WordCount实践
实验十四 在IntelliJ IDEA下编写Spark程序PI和WordCount
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第5小节 数据分析
利用excel和python实现四分位数计算与箱线盒图绘制 quartile boxplot
3.7.2 硬间隔SVM数学求解与例题
全新AI视频模型Vidu 1.5多主体参考生成效果展示
实验五 MapReduce编程案例实战 单词统计WordCount实践
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第4小节 数据清洗
实验二 hdfs HDFS基本操作Shell命令实践( hadoop)
关联规则挖掘FP-growth FPGrowth算法例题解析
用Python进行apriori关联规则挖掘实验
k-means kmeans聚类算法 清晰解释(带算例)
【七天做完大数据毕设】基于Hadoop、Hive和Spark的豆瓣电影可视化分析系统 第2小节 数据采集
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第3小节 数据存储
利用knn对Housing数据集进行数据缺失填充
实验八 MapReduce案例WordCount2.0扩充与Eclipse实现
k-means kmeans的python实现与图像压缩案例
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第6小节 数据同步
实验七 利用Eclipse编译运行MapReduce程序WordCount
实验十三 在Spark shell下 spark SQL读取csv文件进行eBay数据分析查询
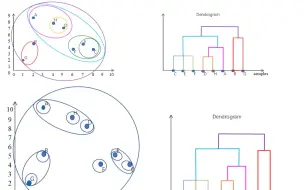
AGNES凝聚层次聚类算法(带实例计算)
信息熵与信息增益概念解释
实验一 熟悉Linux基本操作和hadoop圆周率计算实现 (与实验室同环境)
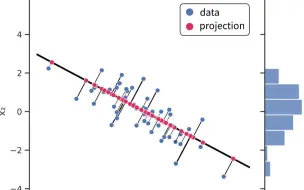
主成分分析(PCA)的python实现(wine数据集)
AGNES凝聚层次聚类在Jupyter Notebook python中的实现(作业例题 mail_customers数据集为例)
皮尔逊相关系数Pearson、Spearman、卡方的python实现
朴素贝叶斯分类算法(带实例) Naive Bayes classifier
knn最近邻算法 带例子example
divisive clustering(DIANA)分裂层次聚类(带计算实例)
【大数据毕设】基于Hadoop/Spark商场数据分析系统可视化(Hive Spark Azkaban Springboot Vue)大数据项目计算机毕设
吹爆!这绝对是中国科学院最出名的科研进阶教程了没有之一,零基础阶段必看的论文写作指南,小白也能很好懂!