V
主页
京.东618红包,每天可领3次
mistral 8*22b:开源大模型第一名再次易主,但吐槽下MOE组织大模型方式是一种鸡肋的方式,相比于单一的大参数模型占用GPU一点都没省,仅仅提升了并发
发布人
mistral 8*22b:开源大模型第一名再次易主,但吐槽下MOE组织大模型方式是一种鸡肋的方式,相比于单一的大参数模型占用GPU一点都没省,仅仅提升了并发或推理速度
打开封面
下载高清视频
观看高清视频
视频下载器
Llama3与GPT4全面对比测评,开源大模型vs闭源大模型,哪个更强?
llama3 70B性能对抗测试,真的比肩GPT4了吗?开源社区王炸?开发这一模型的思路是什么?
近期开源4个MoE大模型哪个最优?DBRX?Qwen?
本地部署 Llama3 – 8B/70B 大模型!最简单的3种方法,支持CPU /GPU运行 !100% 保证成功!! | 零度解说
22GB不够64GB怎么样?
认识混合专家模型(MoE)
八块魔改2080ti显卡跑WizardLM-2-8x22B-AWQ
苹果M2 Ultra:AI大模型的新希望
羊驼3终于等来了!Meta发布最强开源大模型Llama3
mistral-next:接近gpt-4的欧洲神秘的大模型,比mistral-7*8b还要强大的新一代大模型,在逻辑思维、知识、编程能力整体超越了chatgpt
开源社区发力!大神C语言手撸GPT!Mistral AI开源新22b模型!Cohere开源新模型超过GPT4!
使用Mac Studio跑Mistral AI新出Mixtral-8x7B-MoE大模型速度测试(M2 Ultra 76-core GPU 192GB RAM)
Meta发布最新开源大模型Llama 3 | ChatOllama本地知识库问答体验再升级
【官方劝退】为什么不推荐你购买这款 RISC-V CyberDeck 掌机?
万字测评!18个主流大模型深度评测,读懂AI现状【深度模评03】
MiniCPM-2B和MoE-8x2B模型 开源最强“小模型” #小工蚁
油管长视频摘要比较:elmo和本地大模型
不是百亿模型用不起,而是通义千问MoE更有性价比
M3MAX 128G 运行llama2-70B
2080 Ti就能跑70B大模型,上交大新框架让LLM推理增速11倍
小米14安装运行Qwen1.5-14B开源大语言模型(无需联网)
Llama 3终于来了!但感觉没那么兴奋
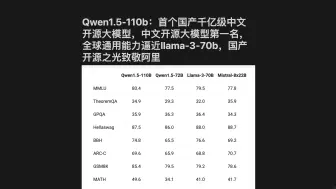
Qwen1.5-110b:首个国产千亿级中文开源大模型,中文开源大模型第一名,全球通用能力逼近llama3-70b,国产开源之光致敬阿里
马斯克最强Grok-1.5V发布,碾压所有大模型,果断放弃ChatGPT
llama3使用m3max和4090的推理速度对比及企业应用
【精校】马克·扎克伯格:Llama3,价值百亿美金的开源模型 |最新访谈完整版2024.4.19【中英】
CodeQwen1.5-7B开源!
华为Pura70 Ultra: 我会伸缩!我:我给你按回去!按回伸缩摄像头,会咋样?
Llama3正式发布,其中70B模型超过谷歌Gemini,马斯克表示很不错
OpenAI开放异步调用API,异步任务会在24小时内返回结果,但是价格是同类型的一半
llama3:meta发布llama3的80亿和700亿参数的大模型,大模型领域即将迎来GPT-4 时刻, 同时llama3增加了生图能力后续会开放多模态版本
SWE-agent:将大模型转变为软件工程师Agent,可以修复 GitHub 项目中的错误和问题,SWE-agent解决了12.29%的SWE-bench问题
RAGFlow:采用OCR和深度文档理解结合的新一代 RAG 引擎,具备深度文档理解、引用来源等能力,大大提升知识库RAG的召回率降低幻觉
开源 VS 闭源:如何选择大模型底座? 私有化落地大模型应用中,如何将llm应用准确率提升到80%以上?
Meta AI重磅发布了: Llama 3!
Perplexica:替代传统搜索引擎的AI搜索开源实现,可平替Perplexity AI实现高效信息获取,终结百度、google等传统搜索引擎
M3 max 48g 跑Llama3 70b 4bit
openAI推出半价接口,该接口24h内才能给出结果。
OpenUI:替代前端的AI工具,使用AI聊天构建前端页面,发挥想象力来描述 UI需求实时渲染,将 HTML 转换为 React、Web Components
AIOS:新一代LLM Agent操作系统发布,开启大模型的windows时代,为提升agent构建和运行效率提供了基础,未来构建Agent会像构建软件一样容易