V
主页
UniColor - 使用 Transformer 进行多模态着色的统一框架 SIGGRAPH Asia 2022
发布人
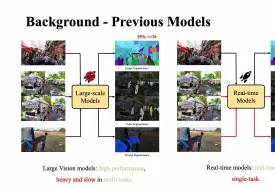
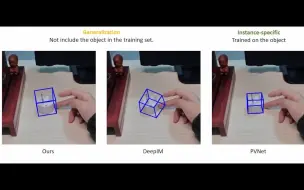
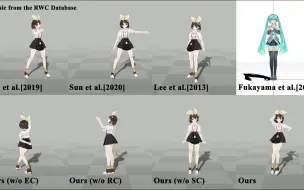
https://luckyhzt.github.io/unicolor 福利:2000核时免费领,立刻开启云上高性能计算 ☞,注册即送200元计算资源,https://www.bkunyun.com/wap/console?source=aistudy 我们提出了第一个统一框架 UniColor 来支持多种模式的着色,包括无条件和有条件的,例如笔画、示例、文本,甚至它们的混合。我们没有为每种类型的条件学习单独的模型,而是引入用于将各种条件合并到单个模型中的两阶段着色框架。在第一阶段,将多模态条件转换为提示点的共同表示。在第二阶段,我们提出了一个基于 Transformer 的网络,由 Chroma- VQGAN 和 Hybrid-Transformer 可根据提示点生成多样化和高质量的着色结果。定性和定量比较都表明,我们的方法在每种控制模态中都优于最先进的方法,并进一步实现了多模态着色以前不可行。 tive 界面展示了我们统一框架在实际使用中的有效性,包括自动着色、混合控制着色、局部重新着色和迭代颜色编辑。
打开封面
下载高清视频
观看高清视频
视频下载器
华科提出UniAnimate:驱动单张图片跳舞,结果逼真
可以跟知网说再见了!中科院推出免费数据库,可检索1.7亿文献资源,强烈建议所有研究生找AI方向的论文用起来!
ICCV2023 | 特征扩散——StyleGAN 中的“致命伤”及其解决方案
CVPR2023 | 扩散模型协作实现多模态人脸生成和编辑
AI视频换脸真的变态死啦!!!
CVPR2023|ECON:显式穿衣人重建算法
南洋理工大学提出VideoBooth:基于扩散的图像提示视频生成
CVPR2022 Oral | 消除图像拼接后的不规则边界!已开源
MagicAvatar:多模态虚拟人生成/驱动
「追踪一切」视频算法来了
CVPR2022 三维目标跟踪 | 融合区域和深度以实现无纹理对象的高效 3D 跟踪
AI走秀:恶魔专场
ICCV23|基于box prompts分割一切!OpenSeeD:简单有效的开放词表图像分割框架
图解何恺明最新一作论文 Masked Autoencoders(MAE)
北大提出RAP-SAM:实时通用Segment Anything
当AI开始反叛人类,人类能否用AI对抗AI,最新科幻异星战境
ECCV 2022!CAIR:用于Instagram滤镜移除的快速轻量级多尺度色彩注意力网络
BlunF:NeRF+2D 蓝图应用于室内设计!支持 3D 操作,例如遮罩、外观修改和对象删除
北交提出StabStitch!消除视频拼接的扭曲抖动
HyperHuman:基于隐式结构扩散的超逼真人像生成
港大&浙大提出Gen6D:从 RGB 图像估计 6 自由度物体姿势
AAAI2023|清华提出StyleTalk:说话风格可控的One-shot Talking Head Generation
ICCV 2023|迭代prompt学习用于无监督背光图像增强
NVIDIA’s New AI - Nature Videos Will Never Be The Same!
CVPR2022 | 基于Transformer进行高质量实例分割的Mask Transfiner
人工智能助力足球比赛!姿态估计、球员检测、跟踪、位置分析全都可行!
ECCV2022| 3D 人体模型拟合新方向:学习顶点下降
CVPR2022 | 基于Transformer的视频插帧算法!支持对视频 8倍插帧
CVPR2023 | MetaAI最新工作ImageBind,全能AI可学习6种不同模态!
ThemeStation:输入少数示例生成主题感知的 3D 模型
CVPR2022 | 谷歌出品!逼真的单目 3D 人体重建
AI领域最有趣的老师李宏毅:模型压缩系列讲解
ECCV2022 | VNext:下一代视频实例识别框架
ICCV2023 | 递归视频车道线检测
暑假最应该做这件事|大学生迟早要掌握的技能!AI教程推荐【建议收藏】
AI 编辑视频!这特效太逆天了!SIGGRAPH Asia 2021
吹爆!这可能是麻省理工最出名的线性代数教程了,想学好线代一定不能错过的《线性代数可视化手册》,看完还学不会你来锤爆我!人工智能|数学基础
ICCV 2023: 应用深度学习技术给动漫线稿插帧!
AI舞蹈动画合成系统,根据音乐自动生成高质量舞蹈! | SIGGRAPH 2021
吴恩达:关于机器学习职业生涯以及阅读论文的一些建议