V
主页
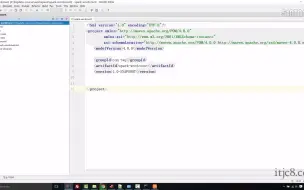
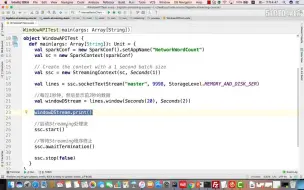
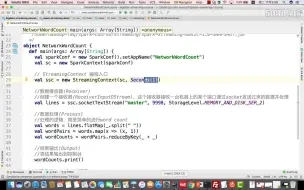
4-13python spark应用的正确提交
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
1-1IntelliJ IDEA开发spark应用
13Spark SQL本地调试读写Hive
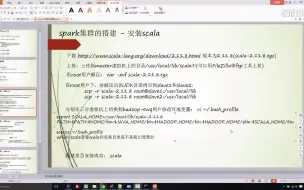
1-4Spark集群环境的搭建
13_练习讲解
1-4监控Spark Streaming程序
1-2实战:本地运行Spark Streaming程序
3-13使用工厂方法
4-17spark-daemon脚本原理以及实现
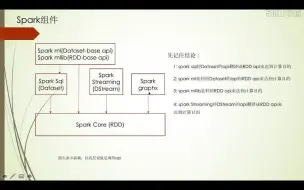
2-8Spark Core组件解决的问题及其特点
1-23Spark Streaming结合Spark Sql
8Spark SQL兼容Hive配置
2-7理解Spark分布式内存计算的含义
4-16spark-class脚本原理以及实现
6-4Spark使用bulkput将数据写入到HBase中
7-3SparkSession的讲解
6-17Spark SQL未来会成为Spark的新核心
2-12Spark Graphx组件解决的问题及其特点
2-1Spark是怎么进行分布式计算的?
6-5Spark使用bulkput将数据写入到HBase中优化
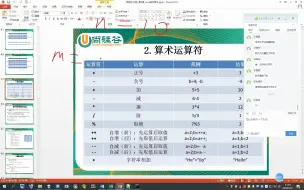
20200321_111113比较运算
6-8Spark Streaming读写Hbase
2-11Spark Streaming组件解决的问题及其特点
3-13shuffle & sort
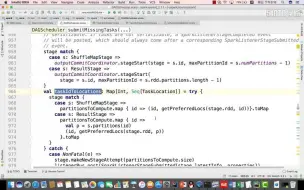
5-18源码讲解之job提交流程
13-改变机器负载、SecondaryNameNode、启用回收站
2-10Spark SQL组件解决的问题及其特点二
2-13Spark ml组件解决的问题及其特点
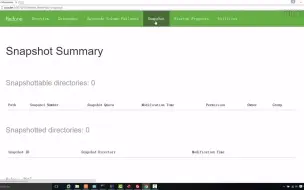
1-13HDFS Web UI讲解
1-13window(窗口) API
1-24Spark Streaming进行网站流量实时监控
6-1Spark在driver端和executor端读写Hbase
1-13HBase技术架构
11Spark SQL代码中写SQL读写Hive
4-8Java版本的Spark streaming集成Flume
2-3Spark Streaming Application原理
4-18SparkSubmit原理以及源码分析
Python零基础入门到精通(2024最新版)
4-6Spark Streaming集成Flume(push模式)
6-15Spark RDD中使用隐式转换
4-13Java 开发Produce 和Consumer(必须搞懂)