V
主页
如何用13B模型击败GPT-4 训练数据被评估数据污染
发布人
如何用13B模型击败GPT-4 训练数据被评估数据污染
打开封面
下载高清视频
观看高清视频
视频下载器
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
GPT-4模型架构泄露:1.8万亿参数 混合专家模型 (MoE) 揭秘
AWQ大模型量化INT4比FP16 推理快2倍,GPU内存1/3
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
Jamba1.5开源大模型同等性能降低10倍KV Cache
阿里发布Text2SQL最新实践开源模型准确度超GPT4
LightLLM轻量级高性能推理框架 和vLLM哪个更强?
通义千问千亿模型比720亿模型更省算力 #小工蚁
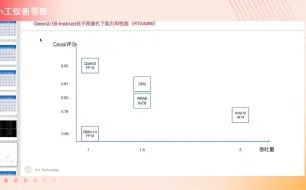
Qwen2-7B-Instruct不同量化方法准确度和性能比较
微调大语言模型如何自动生成 训练数据以及优化技巧
ClickHouse和Elastisearch 深度对比
国产首个开源MoE大模型DeepSeekMoE 16B #小工蚁
SQLEval Text2SQL能力评估实践 #小工蚁
将训练数据打包减少一半大模型训练时间 #小工蚁
如何通过种子任务自动生成数据 训练自己的ChatGPT
StarCoder2-Instruct自我对齐训练数据合成新方法 #小工蚁
NL2SQL大模型生成SQL调研报告
用LLM从文本中自动提取数据 生成表格的新算法效率提升110倍
RAGChecker开源RAG诊断框架
表格式out!大模型最爱JSON,你了解吗?
MiniCPM-2B和MoE-8x2B模型 开源最强“小模型” #小工蚁
利用OpenAI的GPT-4训练的微软小模型,是如何成为最强开源模型的?
大模型微调训练实践 准确度10%提升至90%
Qwen2-Audio语音多模态大模型使用实践 #小工蚁
微软开源DeepSpeed-MoE训练更大更复杂混合专家模型 #小工蚁 #deepspeed
多模态Embedding开源模型 Visualized BGE #小工蚁
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
抱抱脸开源小模型SmolLM和训练数据集 #小工蚁
大语言模型的技术细节 分布式训练和推理(3/3)
BAdam大模型全参训练方法更省显存,速度更快,性能更优
训练大语言模型LLM 如何定义自己训练数据集?#小工蚁
BCE Embedding开源大模型 RAG应用准确度提升关键
基金日常信息发布内容AI审核
企业大语言模型用什么GPU H100/A100还是4090? #小工蚁
谷歌更新Transformer架构MoD 节省计算资源,提高模型性能 #小工蚁
Llama3和Llama2模型全面对比 #小工蚁
混合RAG结合向量RAG和图RAG优势在哪里?
大语言模型快速JSON解码算法 Jump Forward Decoding #小工蚁
人工智能在制造行业应用场景(1/2)
RankRAG英伟达检索增强生成算法 #小工蚁 多个测试数据集准确率SoTA