V
主页
京东 11.11 红包
强化学习论文分享2022-11-17
发布人
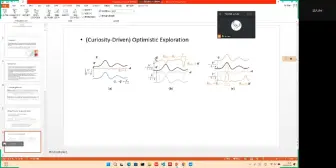
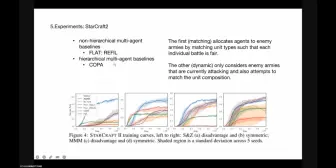
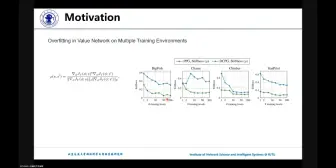
Don’t Touch What Matters: Task-Aware Lipschitz Data Augmentation for Visual Reinforcement Learning > 内容简介:视觉强化学习(RL)的关键挑战之一是学习能够推广到看不见的环境的策略。近年来,旨在增强数据多样性的数据增强技术在提高学习策略的泛化能力方面表现出了良好的性能。然而,由于RL训练的敏感性,单纯地以任务无关的方式应用数据增强对每个像素进行变换,可能会出现不稳定,损害样本效率,从而进一步加剧泛化性能。这种现象的核心是面对放大的图像时动作分布的分歧和高方差值估计。为了缓解这一问题,我们提出了一种基于任务的Lipschitz数据增强算法(TLDA),它显式地识别出具有较大Lipschitz常数的与任务相关的像素,并且只增加与任务无关的像素。 > 关键词:视觉强化学习,泛化,数据增强 Advantage Constrained Proximal Policy Optimization in Multi-Agent Reinforcement Learning(ICLR 2023) > 内容简介:在基于价值的多智能体强化学习中,个体全局最大值(IGM)原则起着重要作用。但是,在多智能体策略梯度方法中,由于随机探索和梯度方向的冲突,IGM难以保证效果。基于多智能体的优势分解引理,ACPPO利用每个智能体的优势网络来估计当前的局部动作状态优势,每个智能体的系数都根据估计的联合行动优势和局部优势的一致性来约束联合行动优势。 >关键词:Multi agent, reinforcement learning, neural network, deep learning, trust region
打开封面
下载高清视频
观看高清视频
视频下载器
【具身论文阅读】Diffuser: 基于diffusion的强化学习规划器
【MPC+强化学习】四大名校教授精讲强化学习和模型预测控制18讲!Actor Critic模型预测控制、策略梯度方法
【论文代码复现122】基于强化学习的路径规划问题||强化学习和群智能优化算法有什么区别
从模型预测控制到强化学习12:DDPG做动态控制-研究生入学培训答疑
【基于深度强化学习的冠军级别无人机竞速】强化学习和模型预测控制MPC中英字幕18讲!
【比刷剧还爽!】太完整了!中国科学院大学和上海交大强联合的(PyTorch+深度学习+强化学习+机器学习)课程分享!快速入门极简单——人工智能_AI_神经网络
强化学习论文分享20240411_2
如何直观理解PPO算法?博士详解近端策略优化算法原理+公式推导+训练实例!强化学习、深度强化学习、李宏毅
强化学习论文分享20240719_1
一步步教AI玩游戏,强化学习通关教程!2024必学AI课程,赶紧收藏学习起来吧!
【中英字幕】强化学习和模型预测控制18讲!四大名校教授精讲模型预测控制、最优控制、强化学习入门
大模型如何增强强化学习?简单粗暴理解大模型训练中的人类反馈强化学习RLHF!PPO算法、ChatGPT背后的数学原理
强化学习论文分享2023-03-02
强化学习论文分享20240613-2
强化学习论文分享20240117_1
强化学习论文分享2022-10-27
CV强化论文分享-20241012
强化学习论文分享20240725
强化学习框架-Legged Gym 训练代码详解
Transformer+强化学习成为双热点强强联合的发文方向
这可能是我见过强化学习和模型预测控制最好的教程!四大名校教授精讲动态系统和仿真、最优控制、策略梯度方法、MPC
DeepMindxUCL《强化学习|Reinforcement Learning 2021》中英字幕
强化学习论文分享20230515
强化学习论文分享2022-09-29
强化学习论文分享2022-12-01
强化学习论文分享20240110
CV强化论文分享20240808
强化学习论文分享2022-10-06
强化学习论文分享20230522
强化学习论文分享20230727
强化学习论文分享20240613-1
强化学习论文分享2022-11-03
强化学习论文分享20230619
强化学习论文分享20240314_1
【李宏毅】强化学习课程完整版千万不要错过!简单明了的PPO算法讲解!深度强化学习、人工智能、机器学习、大模型
CV强化论文分享20240801
强化学习论文分享20240314_2
强化学习专题分享20230801
强化学习论文分享20230417
强化学习论文分享2023-01-05