V
主页
softmax自注意力机制如何使Transformer模型在上下文学习任务表现出彩?
发布人
【关于资料领取】 大家可以关注我后看下信息,或者看下: https://www.bilibili.com/read/cv19092163/
打开封面
下载高清视频
观看高清视频
视频下载器
涨点神器:清华提出新型注意力机制,深度学习论文创新必备!
解锁Transformer的神秘面纱,探索注意力机制的数学之美!Transformer下一个研究重点
直接取代注意力机制,类Transformer新模型跨界视觉任务实现新SOTA,比EfficientNet快3.5倍【论文+代码】
4.词语的数字化表示:词嵌入-最好的Transformer教学视频:通过图形化方式来理解Transformer架构
Transformer提升效率的最好方法:频域核化,成本大幅降低 推理加速
自注意力从掩码语言建模中学到了什么?想摸清楚看这篇综述
深度学习发论文新宠:混合注意力机制 13种创新方法全面汇总
冲破束缚! 多层感知机+注意力机制模型准确率提升至98.85%,这11种新思路学起来
Transformer求解偏微分方程爆火:新SOTA误差直降52%,10种最新求解方法汇总
英伟达发布最新魔改注意力:简单模型结构+全局信息聚合,SimplifyFormer延迟降低37%,吞吐量提高44%
即插即用-2024最新卷积注意力机制模块,秒杀CBAM,空间、通道、多尺度三重注意力机制
卷不动transformer改进?第三代神经网络-脉冲神经网络了解一下,适配时序、图像各任务,能耗降低54%
深挖Transformer模型优越性能原因,梯度Mesa优化算法!【原文+代码】
Transformer新魔改:性能媲美注意力机制,处理长序列更具优势!
VQ(矢量量化)一下子Key:Transformer的复杂度就变成线性了?
Transformer颠覆性发现:像素级运算无需局部性归纳偏置 全新像素版性能再升级
第一本全面介绍Transformer架构的书,包含最全155种相关魔改
Transformer中的注意力还需要吗? 无注意力架构才是AI新纪元的主宰,来看状态空间模型最新进展
魔改transformer大全,最新变体直接替代传统注意力,22种最佳魔改 #视觉主干 #视觉Transformer
顶会项刊=注意力机制+可变形卷积?竟然提速80%,不得不看的11种前沿创新
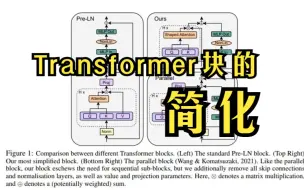
论简Transformer块的重要性!这篇文献给你理好头绪了!大幅提升训练速度和模型效果
新神经网络模型=边界注意力!在任何分辨率下学习寻找微弱边界
“水”论文必备创新点:注意力机制特征融合,12种魔改前沿方法分享
值得关注的CV方向:压缩注意力,多头双向交叉注意力新模块,适用于图像和视频等视觉模态
topos theory视角分析Transformer神经网络,注意力机制居然是关键创新? 含55种注意力机制创新
最新transformer架构登上Nature子刊!高可解释性预测寿命,9篇相关论文文献
中科院一区顶刊:即插即用的多尺度全局注意力机制 【附原文+源码】
知识蒸馏新变革-Hyena:根本解决预训练过程效率 将Transformer蒸馏到长卷积模型
鲁棒卡尔曼滤波2024新算法:基于广义贝叶斯推断计算高效 泛用于在线滤波各种问题
CVPR小目标检测:上下文和注意力机制提升小目标检测,一起来看看吧!
LSTM之父团队力作来了!加速扩散模型牛出天际,简单有效且无需训练 #交叉注意力
Transformer在线性模型上如何做in context learning
【ICCV2023】少即是多的类detr模型:专注权衡计算效率和模型精度,敲强SOTA
名为CAT的卷积增强Transformer:必学的卷积+注意力新混合架构设计
啊?扩散模型与脉冲神经网络梦幻联动?和图像生成高能耗说再见!
[速领]效果暴涨!基于Transformer的最新时序异常检测模型
7.控制输出平滑度的技巧:带温度的Softmax-最好的Transformer教学视频:通过图形化方式来理解Transformer架构
Transformer在时间序列预测中不如线性模型?ICLR 2023给出了这样的答复!
【NeurIPS】2024必将是时空预测爆发的一年!25篇项会一览前沿创新思路
对神经网络做了小改进能发论文吗?10篇故事参考+attention魔改