V
主页
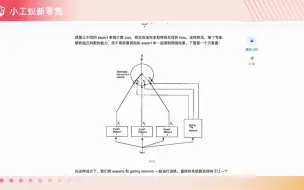
transformers源码阅读——mixtral模型解读——MoE实现细节
发布人
MoE-transformers和传统的transformers有什么区别 Mixtral模型是怎么实现MoE的,源码解读
打开封面
下载高清视频
观看高清视频
视频下载器
第二十课:MoE
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
transformers源码阅读——如何看懂模型代码(以llama为例)
【Mistral模型原理】复现Mixture of Experts(MoE)架构
什么是混合专家模型(MoE)?
【NobleAI】混合专家模型Mixture of Experts(moe)论文混讲
大模型微调新范式:当LoRA遇见MoE(2024.3.2, @Sam多吃青菜)
认识混合专家模型(MoE)
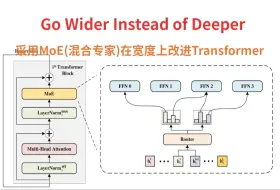
AI论文阅读:采用MoE技术从宽度上改进Transformer
Mistral + MoE 架构解读
图解llama架构 解读源码实现
vLLM源码阅读s1——源码介绍
transfomers源码阅读——Trainer解读系列1_了解训练流程
nlp开发利器——vscode debug nlp大工程(最最最优雅的方式)
国内的大模型结构和llama有多相似?
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
如何优雅的修改transformers包的模型结构——面向nlp小白的开发教程
【AI大模型体验测评系列01】Mixtral-8x7B-Instruct在M1 Pro 32G上的推理速度测试
破解GPT4 - 混合专家模型(MOE)
transformers源码阅读——transformers包的文件框架介绍
起底欧洲最强AI:mixtral,我只能说......
vLLM源码阅读s2——是如何进行离线推理的
chatglm3源码阅读——吐槽角度
GPT-4模型架构泄露:1.8万亿参数 混合专家模型 (MoE) 揭秘
transformers二次开发——为什么要实现自己的sft代码
transformers源码阅读——入门(提高nlp工程师的工程能力)
中文版Mixtral-7x8bMoE25GB显存畅玩专家模型,真·超越GPT3.5!#多专家模型
神秘的MoE模型,是大模型未来的趋势吗
transformers源码阅读——图解mixtral模型——图解MoE细节
不是百亿模型用不起,而是通义千问MoE更有性价比
LLaMA-MoE:基于参数复用的混合专家模型构建方法探索
transformers二次开发——为什么要实现自己的sentence-embedding训练代码
多模态大模型LLaVA模型讲解——transformers源码解读
transformers二次开发——(定义自己的数据加载器 模型 训练器)bge模型微调流程
lora源码解读
大模型量化是怎么实现的——transformers源码解读
像用OpenAI一样使用稀疏混合专家模型Mixtral 8x7B
transformers二次开发——百度轩辕70b大模型数据调度的实现
transformers源码阅读——llama模型调试
使用vscode愉快的阅读transformers源码