V
主页
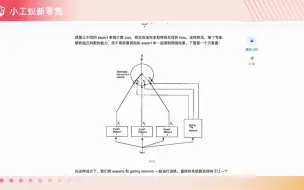
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
发布人
代码放在文档里面 https://dwexzknzsh8.feishu.cn/docx/VkYud3H0zoDTrrxNX5lce0S4nDh?from=from_copylink
打开封面
下载高清视频
观看高清视频
视频下载器
【研1基本功 别人不教的,那就我来】SSH+Git+Gitee+Vscode 学会了就是代码管理大师
认识混合专家模型(MoE)
第二十课:MoE
大模型微调新范式:当LoRA遇见MoE(2024.3.2, @Sam多吃青菜)
GPT-4模型架构泄露:1.8万亿参数 混合专家模型 (MoE) 揭秘
MOE---蛋白结构准备及分析
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
本组Ph.D.录取标准及Ph.D.学生培养计划和目标
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
Mistral 8x7B:究竟什么是MoE(混合专家)模型
作者亲自讲解:LoRA 是什么?
破解GPT4 - 混合专家模型(MOE)
【研1基本功 (真的很简单)Diffusion Model】完成扩散模型!!结尾有bonus!!
微软开源DeepSpeed-MoE训练更大更复杂混合专家模型 #小工蚁 #deepspeed
【研1基本功 (真的很简单)Decoder Encoder】手写Decoder Layer 准备召唤Transformer
DeepSeekV-V2 开局就王炸,国产MOE混合专家模型,人人皆是程序员的时代到来,写代码不再是程序员的专属技能!
神秘的MoE模型,是大模型未来的趋势吗
【研1基本功 (真的很简单)Diffusion Vision Transformer (DiT)】构建DiT核心代码
【PaperReading-大语言模型】MOE的balance loss是怎么做的?
大模型训练:MOE模型架构
450天成为Python核心开发者
【NobleAI】混合专家模型Mixture of Experts(moe)论文混讲
奇葩问题把李沐大神整不会了
LIMoE:使用一个稀疏的专家混合模型学习多种模式
transformers源码阅读——mixtral模型解读——MoE实现细节
【研1基本功 (真的很简单)LoRA 低秩微调】大模型微调基本方法1 —— bonus "Focal loss"
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
LLama3.1为什么不采用MOE?
Mistral + MoE 架构解读
大模型技术栈全览
LORA大模型微调算法原理解析
【研1基本功 (真的很简单)Diffusion Model】构建预测噪声网络
LoRA是什么?| 5分钟讲清楚LoRA的工作原理
什么是混合专家模型(MoE)?
CVPR2024中的多特征融合,附即插即用代码
【研1基本功 (真的很简单)Encoder Embedding】手写编码模块、构建Encoder Layer
OLMoE:基于MoE的全开源大模型
手写大模型代码(上)( LLM:从零到一)【6】
【研1基本功 (真的很简单)Diffusion Model】搞定采样过程(反向过程)
【Mistral模型原理】复现Mixture of Experts(MoE)架构