V
主页
John Schulman: Reinforcement Learning from Human Feedback:Progress and Challenge
发布人
https://www.youtube.com/watch?v=hhiLw5Q_UFg&t=1098s John Schulman: Reinforcement Learning from Human Feedback:Progress and Challenge
打开封面
下载高清视频
观看高清视频
视频下载器
FinRL_ A Deep Reinforcement Learning Library for Automated Trading in Quantitati
Stanford CS234 Reinforcement Learning,RLHF&DPO
John Schulman | Natural Policy Gradients, TRPO, PPO
PyTorch论文复现 | Proximal Policy Optimization (PPO)
斯坦福大学《强化学习|Stanford CS234 Reinforcement Learning 2024》deepseek翻译
(Sergey Levine)Offline Reinforcement Learning
RLHF训练法从零复现,TRL版本复现,代码实战,大语言模型训练
John Schulman | Policy Gradient Methods: Tutorial and New Frontiers
Maximum Entropy Reinforcement Learning
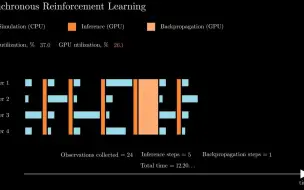
Synchronous Reinforcement Learning
Google || Munchausen Reinforcement Learning
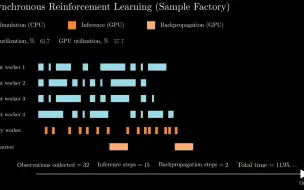
Asynchronous Reinforcement Learning
Pytorch复现论文MADDPG(Multi Agent Deep Deterministic Policy Gradients)
Marc Bellemare | A Distributional Perspective on Reinforcement Learning
Deep Robust Reinforcement Learning and Regularization
ICML 2020 Causal Reinforcement Learning
Challenges for Deep Reinforcement Learning in Complex Environments
NeurIPS 2019 | Reinforcement Learning: Past, Present, and Future Perspectives
2021 DeepMind x UCL RL Lecture Series - Deep Reinforcement Learning-13
ICML 2020 Sample Efficient Reinforcement Learning of Undercomplete POMDPs
Deep Reinforcement Learning and Atari 2600
2021 DeepMind x UCL RL Lecture Series - Deep Reinforcement Learning-12
斯坦福大学《从人类偏好中学习的机器学习|CS329H Machine Learning from Human Preferences》deepseek
Multi-Agent Deep Reinforcement Learning for Connected Autonomous Driving
ICAPS 2020: Tutorial on "Regularization in Reinforcement Learning"
Sergey Levine | Unsupervised Reinforcement Learning
简单粗暴!1小时理解大模型预训练和微调!了解四大LLM微调方法,大模型所需NLP基础知识,基于人类反馈的强化学习、P-Tuning微调、Lora-QLora
太完整了!我居然3天时间就掌握了【机器学习+深度学习+强化学习+PyTorch】理论到实战,多亏了这个课程,绝对通俗易懂纯干货分享!
Stanford CS234 2024 Spring | 强化学习 | Reinforcement Learning
An Analysis of Reinforcement Learning with Function Approximation
RLHF基于人类反馈的强化学习动画讲解(LLM)
斯坦福大学《在不确定性下的决策Stanford AA228/CS238 Decision Making Under Uncertainty》deepseek
Decaying Action Priors for Accelerated Imitation Learning of Torque-Based Legged
DeepMind | The Role of Multi-Agent Learning in Artificial Intelligence Research
【Actuate 2024】中文字幕|机器人基础模型 - Robotic Foundation Models|Sergey Levine
L2 Deep Q-Learning (Foundations of Deep RL Series)
Humanoid Self-Collision Avoidance Using Whole-Body Control with CBF
【DPO衍生算法串讲-Part 1】r2Q*,Step-DPO,RTO,TDPO,SimPO,ORPO
使用ROS2-Control + RL来控制四足机器人
强推!我竟然半天就学会了【强化学习】!(PPO、Q-learning、DQN、A3C)算法原理及实战教你用A3C玩转超级马里奥!(深度强化学习/强化学习入门)