V
主页
PyTorch论文复现 | Proximal Policy Optimization (PPO)
发布人
https://www.youtube.com/watch?v=hlv79rcHws0&t=2642s 本视频分享仅供交流学习,切勿任何商业用途。
打开封面
下载高清视频
观看高清视频
视频下载器
Pytorch复现论文MADDPG(Multi Agent Deep Deterministic Policy Gradients)
RLHF训练法从零复现,TRL版本复现,代码实战,大语言模型训练
John Schulman | Natural Policy Gradients, TRPO, PPO
太完整了!我居然3天时间就掌握了【机器学习+深度学习+强化学习+PyTorch】理论到实战,多亏了这个课程,绝对通俗易懂纯干货分享!
[3] MDPs and Dynamic Programming
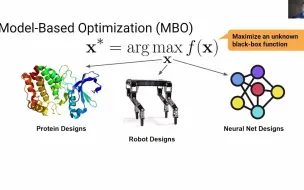
Conservative Objective Models for Effective Offline Model-Based Optimization
这绝对是2024年PyTorch框架天花板教程!清华大佬强力打造!100集带你吃透深度学习!
John Schulman | Policy Gradient Methods: Tutorial and New Frontiers
Marc Bellemare | A Distributional Perspective on Reinforcement Learning
不愧是顶会收割机!迪哥精讲强化学习4大主流算法:PPO、Q-learning、DQN、A3C 50集入门到精通!
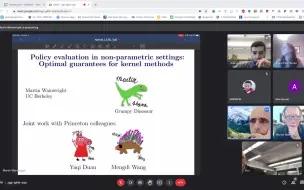
Optimal policy evaluation using kernel-based temporal difference methods
Diffusion Policy 结合 PPO 模仿+强化 (下)
Sergey Levine | Unsupervised Reinforcement Learning
2021 DeepMind x UCL RL Lecture Series - Multi-step & Off Policy-11
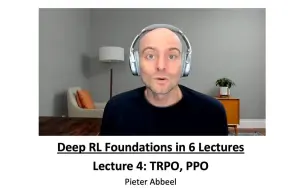
L4 TRPO and PPO (Foundations of Deep RL Series)
Challenges for Deep Reinforcement Learning in Complex Environments
ICML 2020 Causal Reinforcement Learning
Google || Munchausen Reinforcement Learning
L1 MDPs, Exact Solution Methods, Max-ent RL (Foundations of Deep RL Series)
Maximum Entropy Reinforcement Learning
Deep Robust Reinforcement Learning and Regularization
Deep Reinforcement Learning and Atari 2600
DeepMind | The Role of Multi-Agent Learning in Artificial Intelligence Research
L2 Deep Q-Learning (Foundations of Deep RL Series)
2021 DeepMind x UCL RL Lecture Series - Approximate Dynamic Programming-10
2021 DeepMind x UCL RL Lecture Series - Exploration & Control-2
2021 DeepMind x UCL RL Lecture Series - Deep Reinforcement Learning-12
强推!这绝对是B站最全的(python+机器学习+深度学习)系列教程,草履虫都能学会,学不会你来锤爆我!人工智能/机器学习/深度学习/python/神经网络
导师推荐的数据库!4个神级代码复现网站,里面99%的论文都能找到!
ICML 2020 Sample Efficient Reinforcement Learning of Undercomplete POMDPs
【Python】人形机器人——强化学习
L6 Model-based RL (Foundations of Deep RL Series)
(Sergey Levine)Offline Reinforcement Learning
L5 DDPG and SAC (Foundations of Deep RL Series)
Bonsai | Writing Great Reward Functions
吹爆!这绝对是中国科学院最出名的科研进阶教程了没有之一,零基础阶段必看的论文写作指南,小白也能很好懂!
ICAPS 2020: Tutorial on "Regularization in Reinforcement Learning"
通俗理解大模型从预训练到微调实战!P-Tuning微调、Lora-QLora、RLHF基于人类反馈的强化学习
我居然半天就学会了强化学习!华理计算机博士45集精讲,带你一次吃透PPO、Q-learning、DQN、A3C算法原理与实战
2021 DeepMind x UCL RL Lecture Series - Planning & models-8