V
主页
QLoRA一种高效的微调方法,和LoRA有啥不同?
发布人
介绍了 QLoRA,一种高效的微调方法,可以在单个 48GB GPU 上微调 65B 参数模型,同时保留完整的 16-位微调任务性能。QLoRA 通过冻结 4 位量化的前向语言模型来反向传递梯度,并将其转换为低排名Adapters~(LoRA)。我们的最优模型家族——我们称为 Guanaco 的模型,在维京基准测试中比所有先前公开发布的模型表现更好,即使在单个 GPU 上微调只需 24 小时的情况下,其性能水平也达到了 ChatGPT 的 99.3%。QLoRA 引入了多种创新方法来节省内存而不影响性能,包括 4 位正常浮点(NF4)一种新的数据类型,它可以信息理论最优地处理均匀权重。我们还使用 QLoRA 微调了超过 1,000 个模型,并对 8 个指令dataset、多种模型类型(LLaMA、T5)和不可能在常规微调情况下运行的大参数模型(例如 33B 和 65B 参数模型)进行了详细的分析。我们的结果表明,使用 QLoRA 在小型高质量的数据集上微调可以产生最先进的结果,即使在使用比先前 SoTA 更小的模型的情况下也是如此。我们还对 chatbot 性能进行了人类和 GPT-4 评估的详细分析,表明 GPT-4 评估是一种便宜且合理的人类评估替代品。同时,我们发现当前 chatbot 基准测试不可信,无法准确评估 chatbot 的性能水平。通过筛选分析, Guanaco 在 ChatGPT 与其他模型之间的失败方面表现不佳。我们公开了我们的模型和代码,包括用于 4 位训练的CUDA kernels。
打开封面
下载高清视频
观看高清视频
视频下载器
几百次大模型LoRA和QLoRA 微调实践的经验分享
华为910B训练通义千问2-7B LoRA微调实践
S-LORA为数千个LoRA同时提供推理,性能提升30倍 #小工蚁
大模型全参数和LoRA微调哪种方案更好? #小工蚁
大模型微调训练实践 准确度10%提升至90%
比较3种开源大模型Roberta Llama2,Mistrial微调性能
了解大语言模型技术细节(2/3)高效微调方法
华为盘古Pangu-Code2:如何微调出接近GPT4水平的性能?
哪种模型偏好微调最优?DPO、IPO、KTO算法 #小工蚁
微调开源模型具备Function Call讲解和演示 #小工蚁
开源Mistral-7B LORA微调 增强中文能力演示
使用RTX4090+GaLore算法 全参微调Yi-6B大模型
Jina Embedding v3开源多语言嵌入大模型
xllm-stream大语言模型SFT微调多GPU演示
微调大语言模型如何自动生成 训练数据以及优化技巧
LoRA是什么你了解吗? 优化Stable Diffusion的微调
中文ChatGLM-6B预训练模型 5.2万提示指令微调演示
基于LLaMA-2微调中文大模型 千元预算,效果媲美主流大模型
Qwen2.5-Coder写代码大模型技术报告解读 #小工蚁
如何训练企业自己的大语言模型?Yi-6B LORA微调演示 #小工蚁
StarCoder开源代码AI模型微调成编程助手
如何使用DPO微调Llama2,打造行业大模型? #小工蚁 #llama2
探索Falcon模型:构建推理、量化和微调的高效语言模型
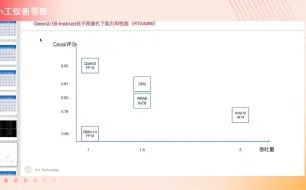
Qwen2-7B-Instruct不同量化方法准确度和性能比较
表格式out!大模型最爱JSON,你了解吗?
什么场景下大模型需要微调?#小工蚁
演示xllm-stream镜像如何可视化微调模型?#小工蚁
用GPTQ算法量化大型模型 大幅减少GPU使用并提高准确率
MiniCPM3-4B开源 4B参数挑战7B性能!真的吗? #小工蚁
ChatGLM2如何进行微调?SSF RLHF QLora #小工蚁
SWIFT阿里开源大模型微调轻量级框架,有啥优缺点? #小工蚁
ChatGLM2如何进行模型微调演示 #小工蚁 #chatglm2
性能媲美CUDA 开源方案助力大模型推理优化 #小工蚁
Self-Memory腾讯发布RAG应用 微调算法
ClickHouse和Elastisearch 深度对比
MEMORAG受记忆启发知识发现的下一代RAG #小工蚁 #rag
传统推荐算法遇强敌:LLM微调后的表现如何?中科大和谷歌为你解答!#小工蚁 #llm #推荐系统
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
LongLoRA长上下文大语言模型的有效微调 #小工蚁