V
主页
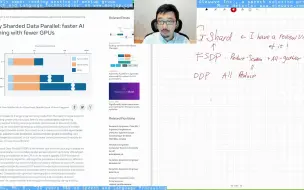
[Short Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs
发布人
Abstract: Fully Sharded Data Parallel (FSDP) is the newest tool we’re introducing. It shards an AI model’s parameters across data parallel workers and can optionally offload part of the training computation to the CPUs. As its name suggests, FSDP is a type of data-parallel training algorithm. Although the parameters are sharded to different GPUs, the computation for each microbatch of data is still local to each GPU worker. This conceptual simplicity makes FSDP easier to understand and more applicable to a wide range of usage scenarios (compared with intra-layer parallelism and pipeline parallelism). Compared with optimizer state+gradient sharding data parallel methods, FSDP shards parameters more uniformly and is capable of better performance via communication and computation overlapping during training. With FSDP, it is now possible to more efficiently train models that are orders of magnitude larger using fewer GPUs. FSDP has been implemented in the FairScale library and allows engineers and developers to scale and optimize the training of their models with simple APIs. At Facebook, FSDP has already been integrated and tested for training some of our NLP and Vision models. My notes: https://blog.olewave.com/olewaves-tech-review-fully-sharded-data-parallel-faster-ai-training-with-fewer-gpus/
打开封面
下载高清视频
观看高清视频
视频下载器
十分钟看懂谷歌铁布衫BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised ...
十分钟看懂脸书虎爪绝户手 - 虎BERT - HuBERT: Self-Supervised Speech Representation Learning
[Long Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs
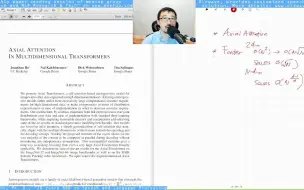
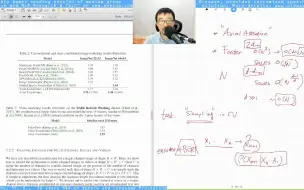
[Long Review] Axial Attention in Multidimensional Transformers
从OpenAI's Whisper模型到你自主研发的语音识别服务: 长音频与流式识别 (第三部分)
原来机器人中也有“人贩子”一个机器人拐跑一大批机器人 #智能机器人 #智能AI #离谱
语音文本技术论文阅读 XLS-R: Self-supervised Cross-lingual Speech Representation Learning a
十分钟看懂微软大力金刚掌WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack
[Long Review] Conformer: Convolution-augmented Transformer for Speech Recogniti
十分钟看懂脸书太极拳法Wav2Vec2.0 -- 语音预训练模型就像绝命毒师老白教杰西
[Long Review] GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
十分钟看懂谷歌金钟罩Transformer以及语音的LAS模型
【人物访谈】10月29日,马斯克接受访谈:AI能力每年至少增长10倍,2028年左右具备所有人类的综合能力|2024.10.29
十分钟看懂谷歌易筋经BERT
[Short Review]Conformer Convolution-augmented Transformer for Speech Recognition
语音文本技术论文阅读 RNN-T: Sequence Transduction with Recurrent Neural Networks
击败OpenAI GPT-4的Claude 3有什么秘密武器?Opus, Sonnet, and Haiku Models, Constitutional AI
[Long Review]Switch Transformers: Scaling to Trillion Parameter Models with
【ChatGPT4.0手机版】国内无需魔法,无限次数使用教程来了!
[Long Review] Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using
[Olewave's Long Review] Efficient Training of Neural Transducer for Speech Recog
语音文本技术论文阅读 One-Edit-Distance Network (OEDN) in Mispronunciation Detection & ASR
[Long Review] Cascaded Diffusion Models for High Fidelity Image Generation
机器学习入门到精通!回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机等十大机器学习算法一口气学完!人工智能/机器学习/深度学习/AI
[Short Review] Axial Attention in Multidimensional Transformers
语音文本技术论文阅读 Branchformer: Parallel MLP-Attention Architectures and E-Branchformer
[Long Review] CLAS: Deep context: end-to-end contextual speech recognition
十分钟看懂谷歌W2v-BERT: Combining Contrastive Learning and Masked Language Modeling
吹爆!这可能是导师都不讲的AI Agent系列课程,公认最适合新手实操的大模型Agent智能体项目,还不会打造专属LLM智能体你来打我!人工智能|机器学习
从入门到提示词工程师:全网最通俗易懂Prompt-Learning提示词学习教程!草履虫都学的会!
CV论文阅读OpenAI CLIP(2/3):Learning Transferable Visual Models From Natural Language
新手狂喜!这绝对是全网最适合初学者入门的NLP自然语言处理教程!清华大佬20小时带你从入门到实战!!!
语音文本技术论文阅读 Scaling Laws for Neural Language Models
1分钟教你用AI实现相声自由!【最强AI声音F5-TTS,一键启动】
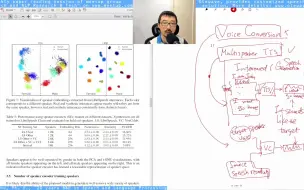
[Short Review] Transfer Learning from Speaker Verification to Multispeaker TTS
语音文本技术论文阅读 UniSpeech-SAT - Universal Speech Representation Learning with Speaker
详解微软零样本语音合成VALL-E
语音文本技术论文阅读 Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recogni
Openai最大的敌人来了,Mistral Ai能不能成为救世主让商用大模型全免费!
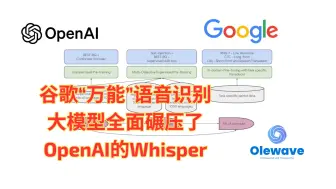
深度篇:谷歌“万能”语音识别大模型USM全面碾压了OpenAI的Whisper模型