V
主页
ResNet最新变体!性能反超Transformer,模型准确率达98.42%
发布人
宝子们在评论区留言或点击主页动态置顶可免费领取视频中资源,无任何套路无偿分享给大家
打开封面
下载高清视频
观看高清视频
视频下载器
融合创新:ResNet+Transformer高性能低参数,准确率达99.12%(附9种融合创新思路)
吹爆!这可能是B站目前唯一能将《基于物理的机器学习》讲清楚的教程了,不愧是普林斯顿,华盛顿大学博士!3小时全面了解!草覆虫都看懂了!真的太强了!
U-Net最新变体!性能连超UNet++/UNet v2,计算量降低160倍
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)
【KAN网络】非线性空间美学的崛起,傅里叶级数转世泰勒展开重生
【精读AI论文】ResNet深度残差网络
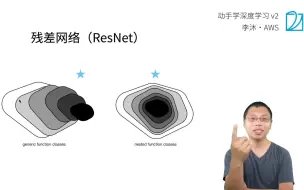
29 残差网络 ResNet【动手学深度学习v2】
三分钟说明白ResNet ,关于它的设计、原理、推导及优点
122集付费!CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气全部学完!
KAN+Resnet项目讲解,融入KAN后指标超越原残差神经网络,学会这个方法融合进任意神经网络
【深度学习缝合模块】废材研究生自救指南!12个最新模块缝合模块创新!-CV、注意力机制、SE模块
荣登《Nature》!小样本学习全新突破,16种前沿创新方法来袭!
全局注意力机制+位置注意力机制,精度提高至99.229%
AAAI2024--Rethinking-attention:浅层MLP完全替换注意力模块提升性能
太...完整了!同济大佬唐宇迪博士终于把【Transformer】入门到精通全套课程分享出来了,最新前沿方向均有涉猎!-人工智能/深度学习
哥们中了一篇CVPR2024,做了一个完整版视频记录
图像分割在这个领域杀疯了!!!基于Mamba做医学图像分割对UNet王炸升级,精度全面超越!
登上《Nature》LSTM+Transformer王炸创新来袭!10种前沿融合创新学起来
卷积一生,不弱于人!新CNN架构挑战Transformer霸主地位!!-深度学习/神经网络/卷积神经网络
CVPR 2024 | 1655FPS,速度巨大提升!自蒸馏MAE是高效的视频异常检测器
性能再升级!UNet+注意力机制,新SOTA分割准确率高达99%
CVPR2024中的多特征融合,附即插即用代码
全局与局部特征融合,超越Transformer,性能提升46%
注意力机制杀疯了!全局+位置注意力机制,精度达99.229%,这个创新方向你一定一定要跟上!
一举颠覆Transformer 最新Mamba刷新多项SOTA,单GPU达140k处理能力!
目前最强Backbone:北大+港大+腾讯+复旦+蚂蚊联合发布,远超ResNet
写论文时总是被创新点、改模型、改代码折磨着?迪哥收集整理了13个论文即插即用模块,快速搭建模型结构,轻松搞定大小论文!
创新结合,卷积+注意力,参数降90%,性能大提升
何恺明刘壮新作:消除数据集偏差的十年之战(神经网络/深度学习/大模型)
24种魔改注意力机制 暴力涨点 即插即用 CNN+注意力机制
为什么Transformer会好于ResNet,从Lipschitz常量讲起【深度学习中的数学ep10】
超越传统卷积!快速傅里叶卷积突破计算极限,加速高达7.93倍
LSTM+Transformer王炸创新,荣登Nature
创新融合!损失函数与注意力机制合力,轻松涨点
【迪哥谈AI】顶会CVPR2024,YOLO-World杀疯了!迪哥手把手带深度解析YOLO-World实时开集目标检测,极其通俗易懂
创新融合!损失函数+注意力机制,点数飙升无阻
llama3使用m3max和4090的推理速度对比及企业应用
参数仅有0.049M!基于Mamba的医学图像分割新SOTA来了!
结合创新!卷积+注意力机制,参数直降90%,性能优化
多模态融合新思路!Attention机制+多模态,暴力涨点