V
主页
什么是 Spark RDD?
发布人
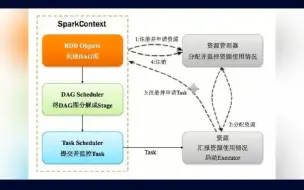
RDD(Resilient Distributed Dataset)是Apache Spark的核心数据抽象,它代表了分布式、不可变、可容错的数据集合。RDD是Spark中用于存储和处理数据的基本单元。以下是RDD的主要特点: 1、分布式:RDD是分布式数据集合,它可以存储在多个节点上,允许在整个集群中并行处理数据。这使得Spark非常适合大规模数据处理任务。 2、不可变:RDD是不可变的,这意味着一旦创建,它的内容不能被修改。如果需要对数据进行更改,通常会创建一个新的RDD,而不是修改现有的RDD。这种不可变性有助于构建可靠和可复现的数据处理流程。 3、可容错:RDD具有容错性,即使在节点故障或数据丢失的情况下,RDD仍然可以恢复。Spark可以自动重建丢失的分区,以确保数据的可靠性。 4、惰性计算:RDD采用惰性计算模型,即在执行转换操作时不会立即计算结果,而是在遇到一个行动操作(如collect、count)时才会触发计算。这有助于优化计算过程,以避免不必要的计算。 5、分区:RDD被划分为多个分区,每个分区是数据的一个子集,通常位于不同的节点上。分区允许数据并行处理,而不需要将整个数据集加载到内存中。 6、依赖关系:RDD之间存在依赖关系,分为窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。窄依赖表示一个父RDD的分区只会被一个子RDD的分区使用,而宽依赖表示一个父RDD的分区可能被多个子RDD的分区使用。Spark会根据依赖关系来调度任务执行。 7、数据转换:RDD支持多种数据转换操作,如map、filter、reduce、join等,这些操作可以用于对数据进行处理、过滤、组合和转换。 RDD是Spark的基本数据结构,它提供了一个强大的分布式数据处理模型,可以应用于批处理、流式处理、机器学习、图计算等各种数据处理任务。由于其容错性和不可变性,RDD是构建大规模数据处理应用的关键要素,同时也是Spark的强大之处。Spark的其他高级组件如Spark SQL、Spark Streaming、MLlib和GraphX都是构建在RDD之上的,使其成为一个多用途的大数据处理框架。
打开封面
下载高清视频
观看高清视频
视频下载器
Spark的核心组件是什么?
Spark支持哪些编程语言?
spark的repartition
Spark的数据处理模型是什么?
Spark中的Shuffle是什么?
Spark中的广播变量是什么?
Spark的内存管理和调优机制
Map 和 Reduce 函数的作用是什么?
什么是 Ingress?
Spark中有哪些机器学习库?
什么是HBase?它与传统的关系型数据库有什么不同?
【七天做完大数据毕设】基于大数据Hadoop、Hive/Spark的民宿可视化分析系统 第1小节-项目介绍
Flink CDC 的实现原理是什么?
k8s iptable 和 ipvs 模式的区别
什么是ClickHouse?
Prometheus 数据采集原理?
Kafka Kerberos 和账号密码认证
Spark,Flink与Hudi整合使用
什么是 k8s DNS(CoreDNS)?
MapReduce 五个阶段说明
什么是 Elasticsearch?
数据湖 Hudi 介绍
Kafka 的工作原理是什么?
Flink CDC 与 Debezium 有何关系?
什么是 etcd?
什么是云原生?
2024最新版Spark视频教程
什么是数据湖?
CGroup 驱动程序 systemd 和 cgroupfs
基于内存型SQL查询引擎 Presto(Trino)
Docker四种网络模式(Bridge,Host,Container,None)
Spark 开源REST服务——Apache Livy(Spark客户端)
k8s 中 etcd 的作用?
Prometheus 高可用实现原理?
MapReduce 的优点是什么?
Flink CDC 如何保证事件的顺序性?
k8s 是如何进行服务发现?
Prometheus 和传统的监控系统有什么区别?
阿里云新加坡SG机房起火-数仓大面积GG【数仓自救、HDFS自救】
k8s 普通日志和events日志区别?